

01 数据资产到底是个啥?
但是这两者都不是我们想要讨论的结构化的,可以再次利用运营的消费者数据assets。
还有一种常见的协助判断的工具,被称为人群资产。
最常见的就是在不同的大厂平台中,会根据各自的人群定义,让品牌可以直观的看到在不同的运营活动之后,人群资产是怎样变化的。阿里系的AIPL(Aware,Interest,Purchase,Loyalty)人群和字节巨量现在的5A人群(Aware-Appeal-Ask-Action-Advocate)都是类似的,基于平台和数据工具进行数据沉淀的人群资产。
基于平台工具的人群资产能一定程度上反映了品牌/店铺在平台内的情况,是一种相对完善的解决方案。但是其主要基于平台方和二方数据,较难直接衡量企业一方数据的健康程度。
我们定义下的消费者数据资产,指的是以一方消费者数据为核心的,企业拥有的数据资产总和。
02 数据资产负债表,一个协助进行一方数据健康水平监测的工具
自由,是基于自有数据的基础上,企业可以自由地使用。不论是自由进行消费者属性的收集(比如,设定喜欢在我的小程序上分享的人标签),自由进行数据分析和挖掘,自由对人群进行再次运营等等。自由意味着可以最大程度上,让数据为运营、业务所用。不过,请注意,自有的数据不代表就是自由的,请往下看。
数据并不是收集之后就结束了,让数据变得可以“自由使用”,挖掘出实际的业务价值才是最终目的。所以,衡量数据是否可以被使用,是数据资产负债表的核心。数据的使用,主要分为两大类:
- 数据分析、优化和验证:包括微观的具体运营活动的评价和衡量,投放和触点的优化,A/B测试;到宏观的衡量品牌整体的消费者状态变化(类似自有人群资产)。
- 个体消费者的再触达和运营:以个体消费者数据为中心的数据应用,这个范围就比较广泛。包括投放中的二次利用,私域再触达,用户分群,CRM优化等等。
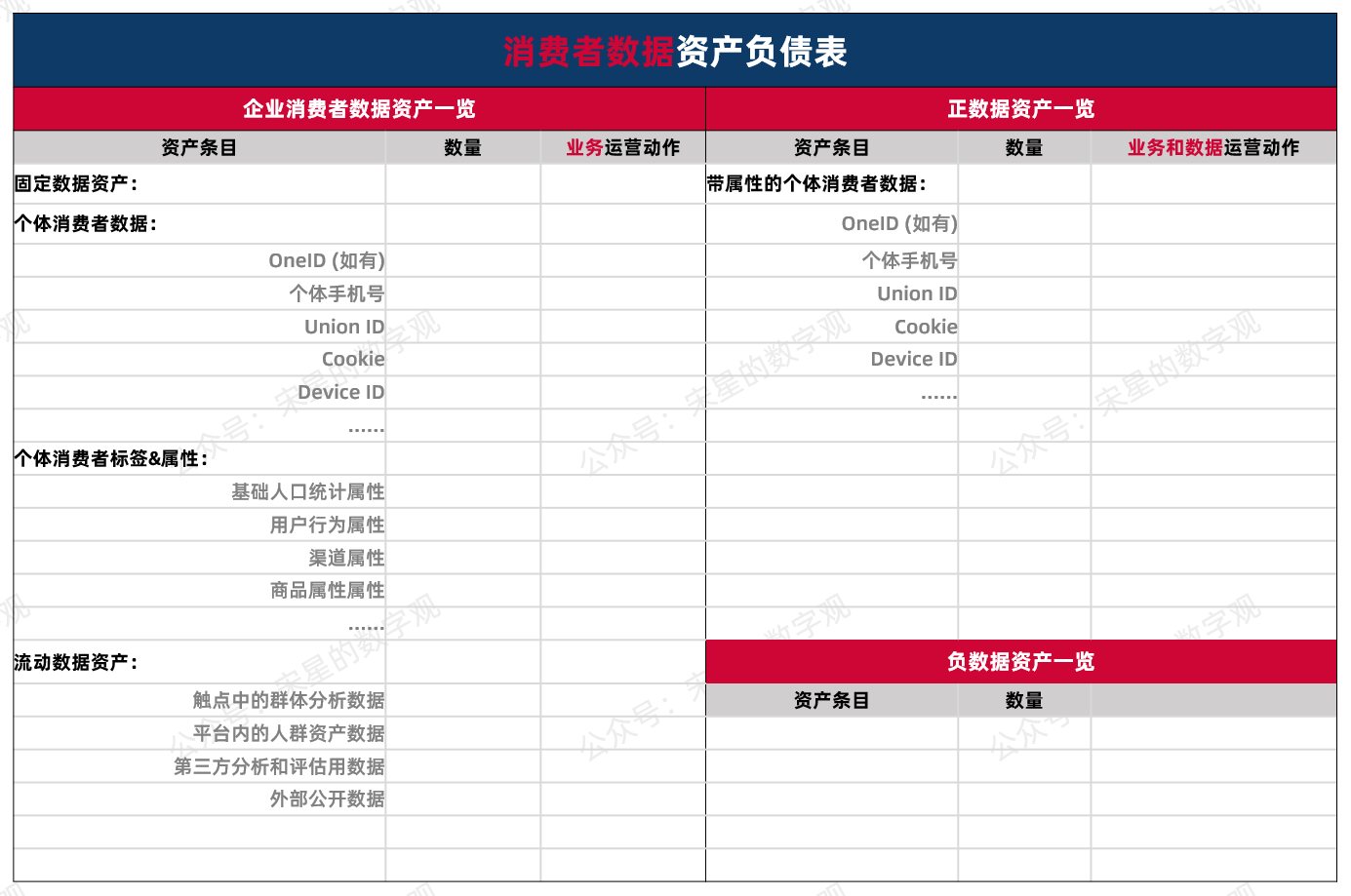
数据资产负债表可以表直观的展示企业现在手里的消费者数据到底能不能起到上面提到的两种应用方法。如果能,有多少能,有多少数据不能。
总结一下,首先,数据本身要成为资产,必须是一方的自有可自由使用的数据。出于数据是否可以使用这个核心目的,我们可以拆分出两种类型的资产:可以被应用的数据正资产和不能被应用的数据负资产。
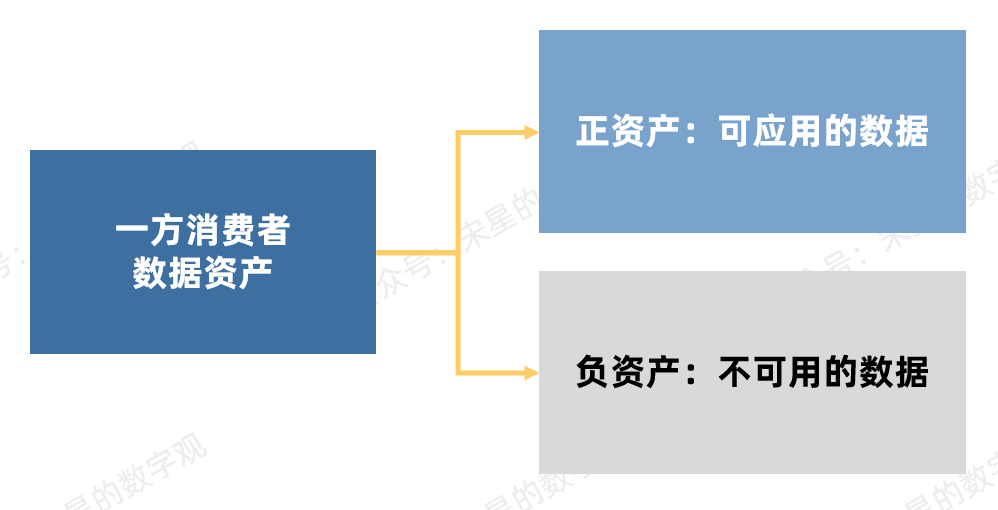
03 数据资产盘点:固定资产和流动资产
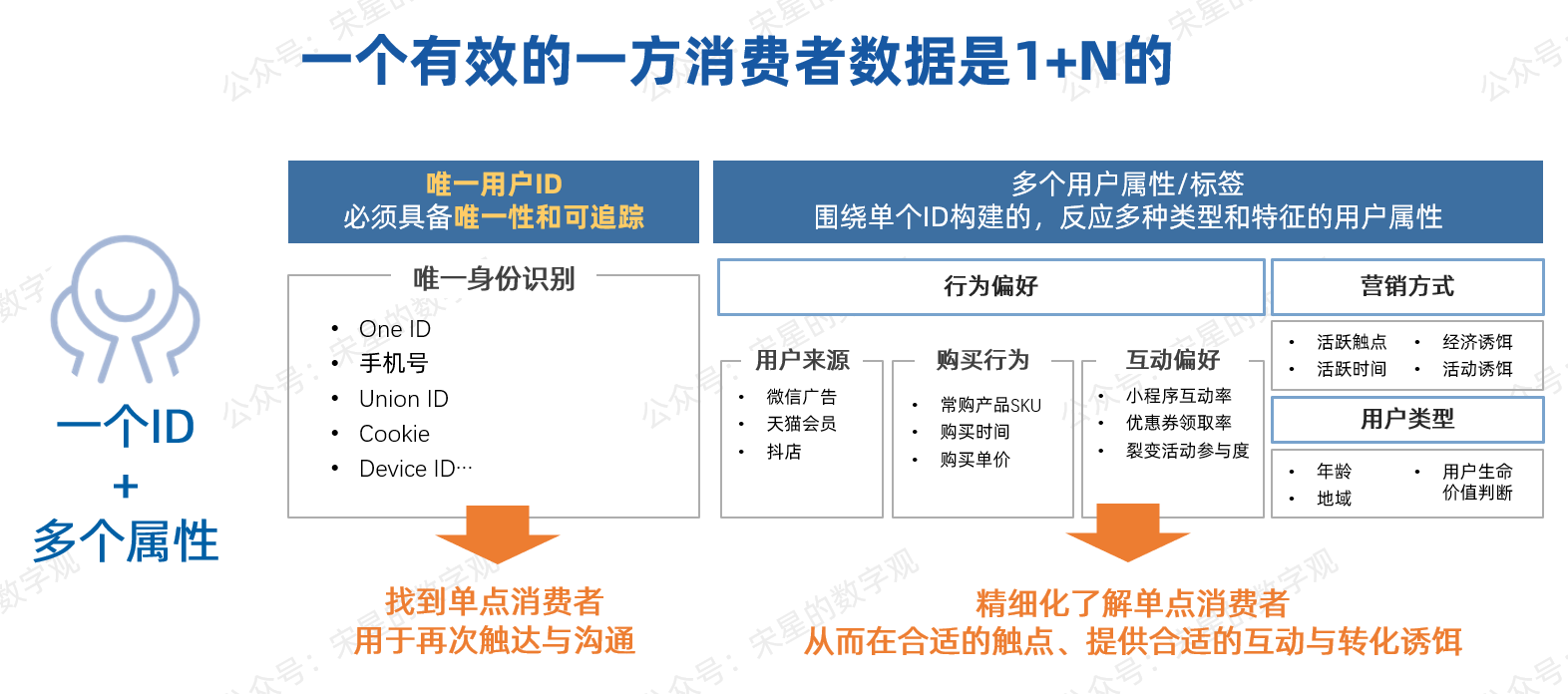
- 唯一身份识别ID范围非常广泛,包括常用的手机号、Device ID(满足个保法下收集的)等。有些企业会直接用One ID的概念来进行拉通的话,One ID也会成为重要的来源。
- 属性,或者说属性构成的标签,是围绕单个个体ID产生的。ID和属性就像是1和0的关系,缺乏了1(ID),后面再多属性都只是空谈;你只有1(ID)没有0,数据的价值只能停留在个位数。
- 要注意,资产盘点的时候目的是对现有资产进行一个完整的摸底。所以这里采取“应收尽收”原则,不进行去重。
第二种资产:流动数据资产,根据不同的运营活动产生的群体数据,协助分析每个运营动作效果
第二种资产都为群体数据,会根据不同的营销活动发生变动。因此定义他们为流动数据资产。这些数据资产更多是起到协助具体营销活动的分析作用。
- 各种触点内的群体分析数据,特别是自有触点在数据埋点之后获得的分析数据;
- 平台内的人群资产,典型的包括5A人群变化,AIPL人群变化等
- 第三方分析和评估用数据,包括一些媒介DMP内的大盘数据,通过调研获得的品牌资产Index等;
- 外部报告数据,这是时间角度来说最长的一种。可能是整年角度,对品牌,甚至行业的整体判断。
需要注意的是这些数据虽然大部分都不是一方数据,但是却可以在不同程度上反映营销活动在具体平台不同消费者中的影响情况。因此,他们都是流动的数据资产。无法沉淀数据,但是可以作为一种衡量营销活动的方式。
请注意,所有的数据数据不是凭空产生的。数据,特别是一方自有数据,均是在日常的运营工作中产生的。也就是“没有交互,就没有数据”。
因此我们在每个资产后面,都增加了一列对应的业务运营动作。意思是说,某一些数据的增长,是由对应的营销动作带来的。这样一方面,可以更直观地看到具体运营动作对数据增长的贡献;同时,也是协助运营同事在策划的时候,反过来自查在具体的一次营销活动中,是不是有遗漏的数据需求。让资产负债表在实际工作中起到作用。
04 正资产和负资产 – 可用的数据和不可用的数据

- 确定唯一的ID:经过清洗,拉通去重的唯一ID。
- 一个时间段内活跃的ID:不活跃的ID本质和废ID没有差别,但是具体的活跃时间段要从产品和品牌自身的情况出发设定。
- 有属性的ID:有至少2种类型属性及以上的ID。但是具体的数量设定、是否有必有的属性等,都要根据实际运营需求和企业场景出发。举个最简单的例子,一次性公域流量引入转化的场景和提升复购的场景中的属性ID要求就完全不同,此处切不可固化标准。
正资产的这几个标准,实质是对固定数据资产提出了进一步的要求。
一方面是数据标准化和数据清洗的要求。比如要能获得唯一的准确的ID,前提至少ID的命名规则定义要保持一致,数据获取要有规范,数据清洗要有流程和标准等。
另外一个方面是对企业是否能通过运营丰富ID的属性,增加1后面的0的能力提出了要求。越多与运营直接关联的属性/表现,越能够增加对用户洞察、运营优化以及数据挖掘的潜力。例如老客再运营增加标签属性和活跃度,增加触点中的交互点,都是可以达到增加正资产的目的。
所以,在正数据资产后面关联了数据和业务的运营动作,方便查阅和判断具体正资产的增长渠道。
增加可用的,可再次运营的个体数据,是营销数据化运营的最终目的。要让数据资产负债表的资产状况更加健康,其实就是对数据运营团队和营销运营团队提出了双重要求。不仅仅是要建立一个可以让数据更加干净的数据标准体系和SOP,同时也是让数据增长成为运营活动的闭环之一。
增加数据正资产,让正资产可以进一步在运营中被运营,从而提升整体的数据价值,是设置数据资产负债表的核心目的。因此,如果你对自己的数据有了明确的资产摸排之后,甚至可以将负债表的资产优化情况作为过程KPI的一种。
05 用数据资产表,尝试做一次自审
- 假设一个企业拥有百万级别的个体消费者数据在CDP内,拥有淘系、抖系店铺和小程序电商。想要对自己的数据资产水平进行审查的话,应该怎么做呢?
- 第一步,我们先来进行固定资产中ID的盘点:
- 首先,最多的是手机号,主要是通过各方电商会员和购买获得。其次是小程序本身,登录和购买分别会带来手机号和Union ID。最后有一些官网留存的销量Cookie和投放获得的Device ID。
- 关于属性,我们将记录已经生成的标签的数量。盘点后发现,这个品牌的数据增长主要来源还是购买相关的会员获取,因此其购买行为标签相对丰富,但是关于内容,活动参与度等行为的属性相对匮乏。
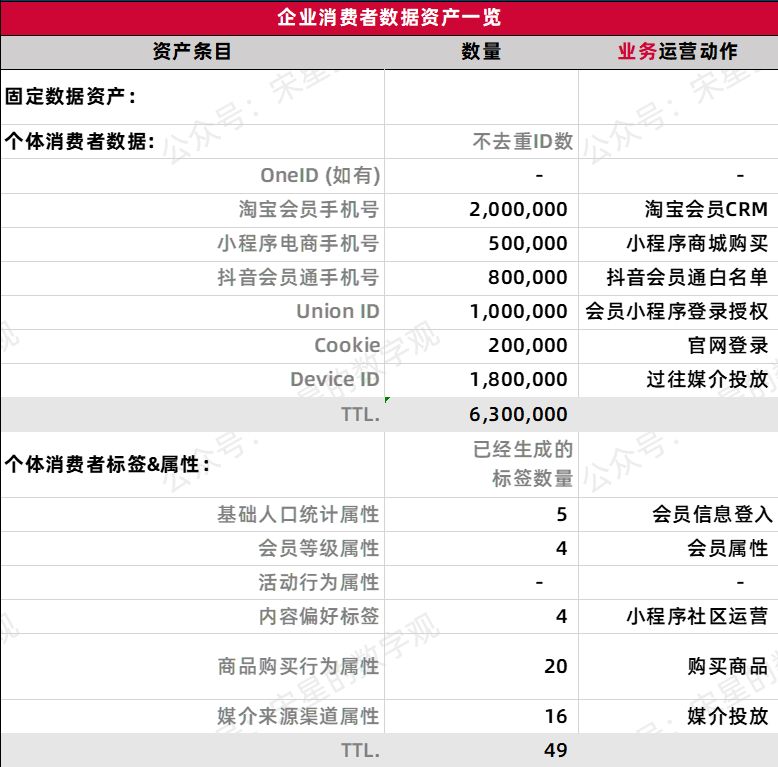
- 活跃的时间段定义:该快消品牌的过去一个用户的购买到二次购买周期大概在3个月,我们设定活跃的有价值的ID在6个月。
- 同时,业务角度主要的运营方式是实现忠诚用户的积累,从而带动复购,跨品类的购买升级。因此,我们定义至少需要覆盖2种标签:购买行为标签 & 基础人口统计属性
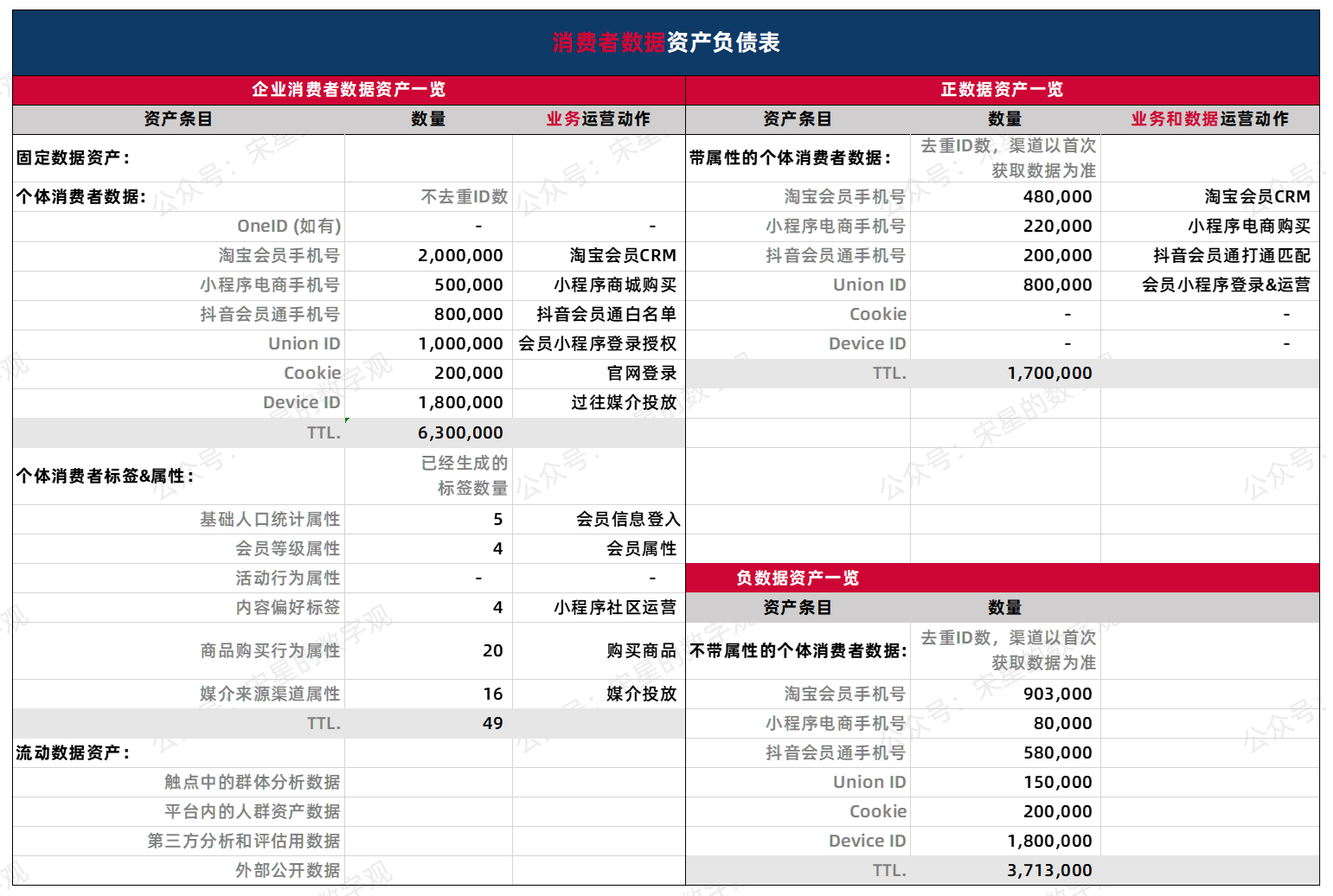
- 总体去重后的数据总数大概在500万,重复数据去除了100万左右,状况相对良好;
- 主要去重数据在Union ID上,反而说明会员私域有效的汇聚了一些在其他渠道购买的用户;且会员小程序能获得最多的标签,其数据资产价值高;
- 抖音总去重后总用户在780万,基本没有重复,多为新用户;但是抖音用户标签获取过少,让该类资产成为了无用资产或价值并没有非常显著的资产。
- 鉴于该企业的数据应用场景为复购为主,Cookie和Device ID在该场景下属于无效数据(但是并不代表在其他场景下他们没有价值,仅以某一个场景举例)。
由此,企业后续的数据运营目标就非常清晰了:着力在抖音新用户中,将他们汇聚到私域会员中,通过会员活动获取更多属性,从而精准的进行二次运营提升复购机会。
上面只是基于某一个数据场景进行的举例,实际的业务情况一定会更加复杂。整个企业的数据资产,需要按照所有场景的总和,数据管理和数据清洗的现状等情况进行综合判断。
希望数据资产负债表,可以提供一个框架性的数据健康状况自查的思路,实际帮助大家解决一些问题。