

01.淘天生态数据动向
02.微信生态数据动向
03.社媒平台:小红书KFS投放玩法究竟是什么?
04.营销技术工具数据应用动向
01 淘天生态数据动向
前段时间发的文章:《电商平台进一步收紧消费者数据,品牌商家如何应对》,被A Li要求删除,原因是说文章里面写的第三方能有秘钥能解天喵的加密订单数据是“哗众取宠”。
这篇文章就不开放了,放在了知识星球,加入星球的朋友可以自己搜索文件查看。加入知识星球方式见文末。

2)天猫不再给“口子”
天猫不再给“口子”,包括 ISV 第三方也没有这个口子了(密文解密不了了)。想拿天猫的会员数据,自己得首先要有该会员在自己的 CRM 中。所以,自己的会员私域更重要了。另外还有三个信息点:
- 会员手机号很早就不明文了,只是有几个头部品牌有暂时的绿灯(比如数云);
- 订单手机号22年平台就出过通知,所有erp供应商一年内完成整改,延迟到今年已经是照顾商家了;
- oms接口在19年就已经是白名单发放了
02 微信生态数据动向
Question:
你可以认为腾讯如翼就是腾讯广告的DMP。实际上腾讯自己不叫自己的产品“腾讯如翼”,而是“腾讯广告如翼”。它是腾讯广告为广告主设立的数据平台。
既然是DMP,它要发挥的功能场景实际上和大部分广告平台的DMP相比,并没有本质的变化,主要的功能还是投放人群圈选、人群洞察、出价策略和报表数据查看。
但它有一些改进,这些改进不仅是对过去腾讯广告自己的DMP的升级,跟其他的DMP相比,比如巨量引擎的星图、阿里的数据银行相比,也有区别。
主要值得关注的点是:
1. 对腾讯多个触点的数据进一步打通。我们知道底层数据打通情况不佳,这个问题是腾讯广告比较长时间以来被诟病的。数据打通不佳,有几个后果。一个后果是做人群划分的时候,不够好;另一个后果,是投放的算法不够好;更严重的后果,想用大模型做广告投放,数据跟不上,大模型就跑不起来。现在腾讯广告如翼宣称把这些底层数据都打通了。实际上不是如翼打通的,而是如翼是在这些数据打通基础之上建立起来的。另外,基于这些打通的数据,腾讯的大模型叫混元才能更好工作。混元的主要用途之一,也是支持腾讯广告的投放系统。
2. 腾讯广告如翼增加了一个R0人群。这里的R,是腾讯广告树立的5R理论。5R,类似于阿里的AIPL(A),或者字节的5A。腾讯的5R,也是用5个R开头的单词,描述用户从awareness到loyalty的整个过程。具体5R,分别指Reach(R1)、Respond(R2)、Resonate(R3)、React(R4)、Ripple(R5),(触达、回应、共鸣、行动、信赖)。
那么,R0,又是啥呢?R0是如翼定义的,R1之前的人。也就是我们说的TA,目标人群。是你的目标人群,但是还没有被触达到。如果触达到了,就是R1了,如果转化了,就是R4了。所以,R0是Target Audience,是目标人群。
3. 如翼把R0-R5的人群资产的划分,扩展到了自然流量。也就是说,不仅仅只是广告投放流量,也包含腾讯生态内的自然流量。所以,如翼这个工具就不仅仅能在投放效果上做反馈,更可以在投放上做更广泛和针对性的人群圈选。
4. 如翼在人群数据洞察上,有所提升。这个其实也是数据打通和底层升级之后带来的好处。增加了人群标签,进一步细化了人群划分的颗粒度。所以,如翼在帮助广告主形成投放策略上有比较好的作用。
那么,它值得用吗?
显然,数据工具多多益善。在洞察上的作用肯定是很有价值的。具体广告投放效果,为品牌广告主服务居多,所以效果这个层面上具有一定的模糊性。问了几家品牌企业,说,还可以,给我的信息相对比较模糊。
官方举的案例,见下图。

2)如何利用AI降本增效,让视频号10倍增长
知识星球里的杨旭老师独家授权我分享的关于视频号红利的deck。极为详实。视频号的机会和红利尽在于此!杨旭老师是行业大牛,他的内容都是精品!
需要的朋友圈知识星球里搜索“视频号10倍增长”,即可下载文件,加入知识星球方式见文末。
03 社媒平台:小红书KFS投放玩法究竟是什么?
KFS确实是小红书很重要的玩法。但肯定不是唯一玩法。
KFS一般是对品牌企业在小红书上进行营销的必要手段。K是指KOL,其实可以更广义地去理解为内容,就是你找KOL或者KOC发布内容,甚至也可以是自己发布内容。
F是指Feeds,是指对你发布的内容,在小红书上做花钱的推广。没错,就是做广告投放。投放方式,要么是走聚光平台(对企业,尤其是有米的企业来说,这个方式更适合);要么是做薯条加热内容,这个方式比较灵活,但性价比肯定没有那么好。
S是指Search,在小红书上是指看到了相关内容的用户,搜索与你品牌、商品或服务相关的内容。
KFS实际上就是小红书整个品牌推广的核心阵地了。
当然,KFS不是简单的拼合,而是有自己的方法论的。
KFS,我认为,最核心的一点,是要从S开始反推。反推的核心在于,你要传播的信息,是要能通过一个“独一无二”的关键词去表达的。这一点很重要。因为KFS最终的落地,是在S上。我在ASP模型中也强调S,S代表着极强的兴趣,有很大的可能性促成购买。而ASP模型中的S,其中一个重要的承载平台也就是小红书。
所以,对做小红书营销而言,一个很核心的指标就是“回搜率”,是看了与你相关的内容之后,搜索相关关键词的比例。
所以,一定一定要在传播内容的时候,强调你的“独一无二”的关键词!
然后K阶段,打造包含这个关键词的内容,无论你自己做,还是找KOL、KOC做。这里面的策略比较具体,就不在这里详细讲了。简单说一下,钱(预算)多,做金字塔模式(顶级KOL、KOL、KOC、素人依次购买且越到底层类行数量越多),钱少,做中腰部,或者做大量KOC和素人。当然,这个策略只是泛泛策略,具体根据你的产品和阶段,要做调整,不赘述了。
K阶段核心,还是要有内容的数量,小红书是一个大众平台,只做少量KOL覆盖肯定不够。无论预算有钱没钱,内容数量都是重要的。不能总想着一下子就能搞多个爆款,而是要从多个内容中,慢慢“养”出爆款。
这个“养”,当然可以慢慢来,也可以加速一下。怎么加速?那就是通过“F”,也就是Feeds。这就是F的价值所在了。
当你发出的内容,你觉得比较好的,有价值的,或者能看出来有增长潜力的。你再用Feeds广告,就试前面说的“聚光”、“薯条”去加热,去引来更多关注的人群,这样起到事半功倍的营销效果。
有了关键词,又通过K和F阶段对这个关键词及相关内容做了大的曝光,那么就可以看S的表现了。一般而言,K和F阶段做的不差,S不会太差。
不过S,也不是守株待兔,静待花开。S也有讲究,那就是在K阶段的时候,要在发布的内容上对小红书搜索做优化。跟搜索引擎SEO的优化是一个意思,当然,方法肯定不同。
小红书上的SEO方法,强调的是内容的相关性、关键词密度,以及用户互动情况。三者中,前二者是基础,后一者具有决定性。Feeds的流量引入,一定程度上能增加用户互动情况,从而让你的内容能够有更多机会被用户搜索到。
所以,你看,KFS,三者不是独立的,不是拼合的,而是非常有机联系在一起的。
就说这么多,应该能够解答你的问题了。
04 营销技术工具数据应用动向
Question:
有些广告主介意自己的消费者ID上传给媒体,哪怕是加密了,这些广告主仍然觉得自己的消费者ID会通过撞库被媒体掌握。比如,奥迪说,我可不愿意把我的消费者ID上传给媒体,要是上传给了媒体,媒体就知道这些ID背后,是我的消费人群,媒体就可能转手把我的这些ID用于给其他车厂进行营销所用,比如给宝马或者特斯拉投广告,就直接投放给这些ID。
隐私计算可以解决这个问题,即广告主ID保密情况下的ID匹配与数据应用。这种基于各方共有ID并在匹配ID(撞库)之后进行的相关计算,被称为“纵向联邦学习”。
另一些广告主,则有更高的要求,他们说,我的这些消费者,不仅仅只有ID,还有很多ID背后的属性,这些数据,能不能跟媒体或者第三方的数据结合起来,用于更好地洞察消费者?或者结合起来更好地圈选消费者?不过,这些属性不能透露给媒体或者第三方,也就是说,要在不给媒体或者第三方提供数据的情况下实现基于一方、二方(或三方数据)相结合的人群洞察和圈选。
这也是隐私计算可以解决的问题,即在不共享消费者属性数据的情况下,实现对属性数据的应用。
这些应用对于实现一些重要的数字营销场景至关重要,毕竟,数据如果不能够连通起来,数据的价值就大打折扣,数据在数字营销上的作用就得不到充分发挥。可以这么说,今天的数字营销,如果没有隐私计算的帮助,很多高级的玩法都无法实现。
我们先看看“广告主ID保密情况下的ID匹配与数据应用”问题如何通过隐私计算加以解决。
—在ID保密情况下的ID求交与数据应用—
前面说了,ID保密是广告主在意的,他们不希望自己消费者的ID被媒体知道,以免媒体把自己的ID也用于自己竞争对手的推广。但自己的ID总是要跟媒体的ID做匹配的,一旦匹配了,那岂不是自己的这些ID,媒体就完全知道了。
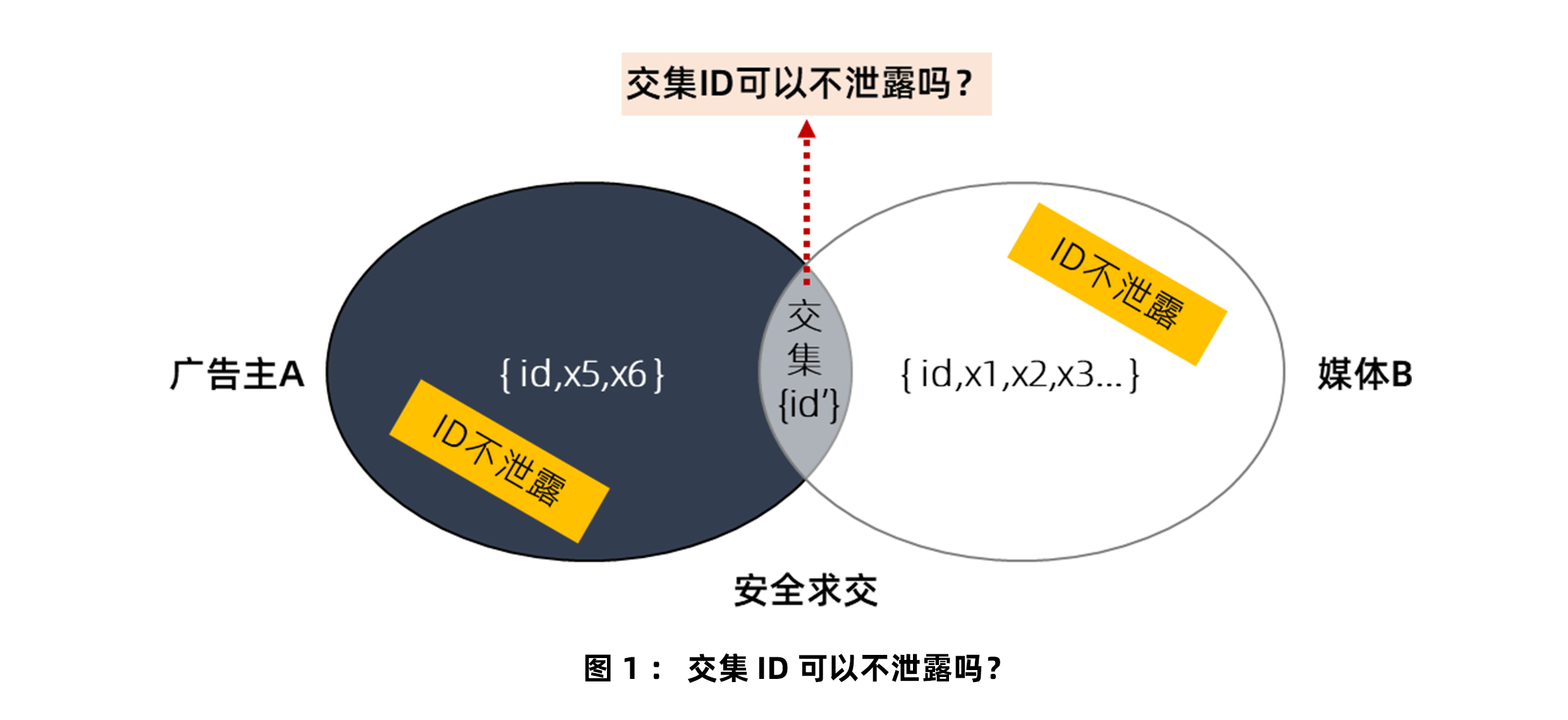
因此,必须解决这个问题。
利用差分隐私实现匿踪安全求交
这个问题的解决,要靠加入一些“混淆ID”。所谓“混淆ID”,也叫“随机噪声”,就是广告主在跟媒体匹配的时候,额外随机添加很多其他与广告主消费者不相关的ID。这样,媒体就不知道广告主真正的消费者到底是哪些了。
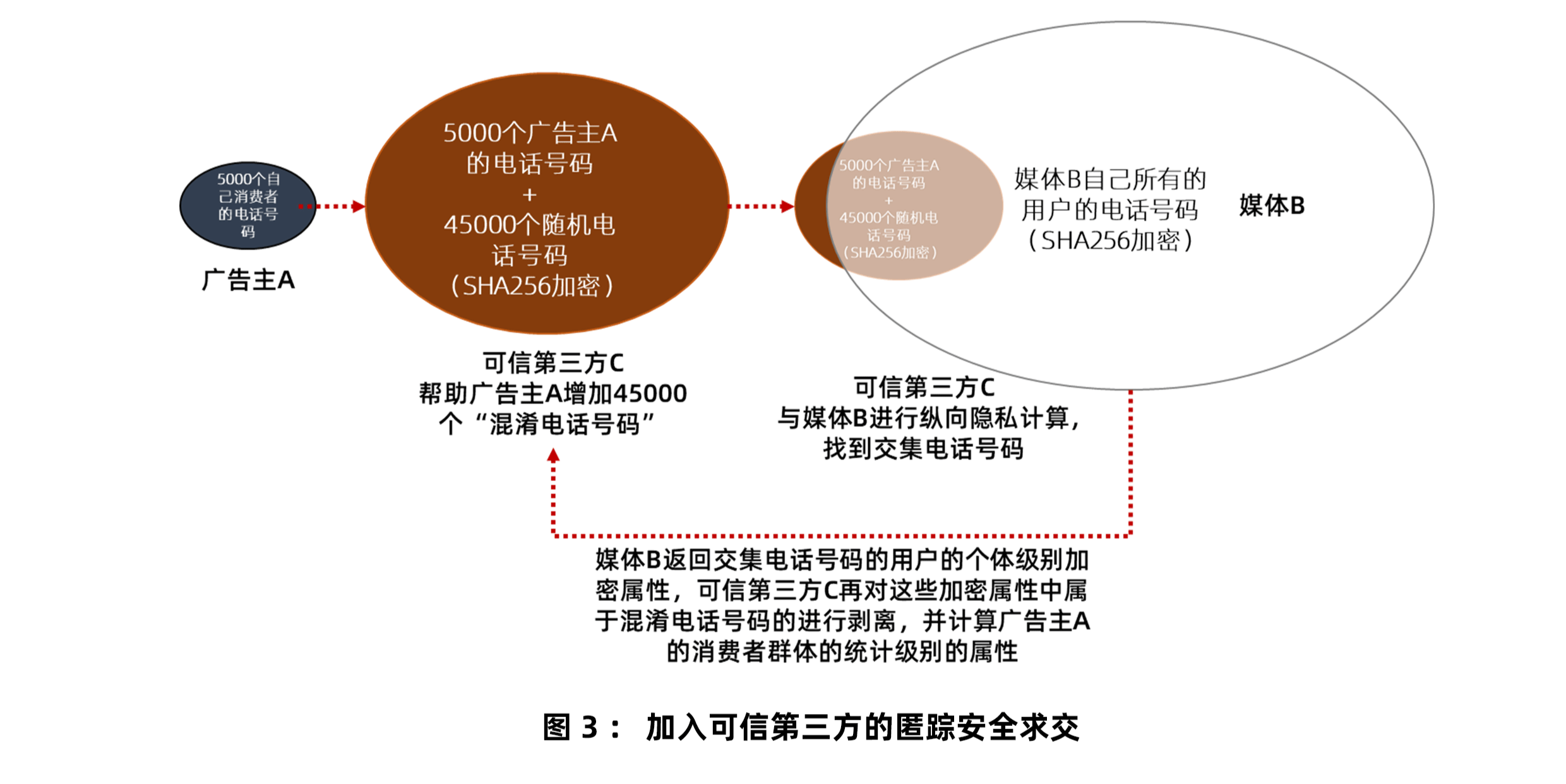
比如,A是广告主,自己的消费者手机号码有5000个,想要跟媒体B进行ID匹配。但为了不把这些ID暴露给媒体,于是又掺杂了45000个其他的手机号码。这样,凑齐了5万个手机号码,跟媒体匹配。
媒体,当然也就不知道这5万个手机号码中到底哪些是广告主的消费者了。广告主的ID就此实现了保密!
这种利用“掺混淆数据”保护秘密(隐私)的方法,被称为“差分隐私”。差分隐私有很多方法,这里讲的只是一种最容易理解的方法。其他各种掺入混淆数据的方法,要基于各种各样的算法,以保证混淆的效果,这里就不多介绍了。
加入了差分隐私的ID匹配,也被称为“匿踪安全求交”。
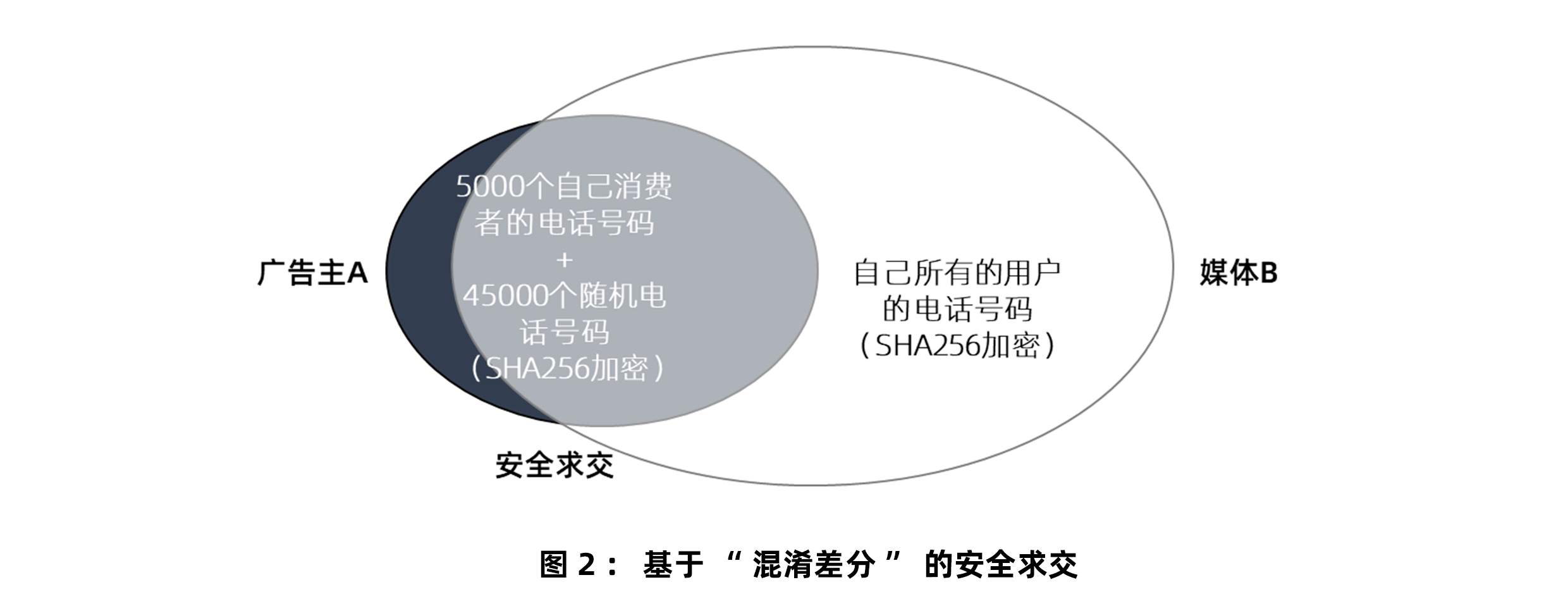
图2:基于“混淆差分”的安全求交(见附件)
讲到这里,你肯定会一头雾水了。按照这样的匹配方法,广告主的数据岂不是也被污染了?比如,广告主要找跟自己已有的这5千消费者相近似的人群,结果,媒体按照的却是“掺水”的5万个人群去寻找近似人群。广告主虽然保住了秘密,但是营销效果却南辕北辙了!你的担忧不是多余的,这绝对是非常重大的问题。为了解决这个问题,需要再引入一些新的东西。
这个新的东西,是媒体和广告主中间的一个可信第三方。
—可信第三方—
还是回到前面这个例子,A是广告主,B是媒体,那么这个可信第三方就是C。C的职责很重要。
广告主(A)要把自己的5000个手机号码加密发给第三方(C),然后C帮忙再掺入45000个起混淆作用的手机号码。
然后C帮助A,跟媒体(B)进行数据匹配。匹配完成后,B将自己的数据结果(个体级别的用户属性数据),以加密的形式发给C。
C针对B发回的加密属性,把混淆ID的加密属性去掉(剥离),然后计算广告主5000个手机号码中能匹配到的那些人的加密属性,并且归纳出这些人的共性特征。这些共性特征,不再带有个人属性,而是统计级别的数据,所以不再涉及到广告主A的消费者的ID。并且这些共性特征是由媒体B发来的加密属性计算出来的,因此,也是加密状态。
第三方C再把这些共性特征返回给媒体B,媒体把这些加密状态的共性特征解密,之后寻找与这些共性特征相同或者相近的人群,帮助广告主进行广告投放。
—同态加密—
你肯定又有问题了,为什么C计算的是媒体B发来的加密的个体属性。加密之后,还能计算吗?答案是,能。因为隐私计算有另外一个技术,叫“同态加密”。所谓同态加密,就是计算原文(明文)的结果,和计算这些明文加密之后的密文的结果,是完全一样的。如果原文用了某个算法和秘钥进行了加密,那么加密之后,做“加减乘除”以及各种各样的数学计算之后得到的结果,再利用该加密算法和秘钥解密之后,得到的结果,和直接用明文做同样的数学计算得到的结果一样。
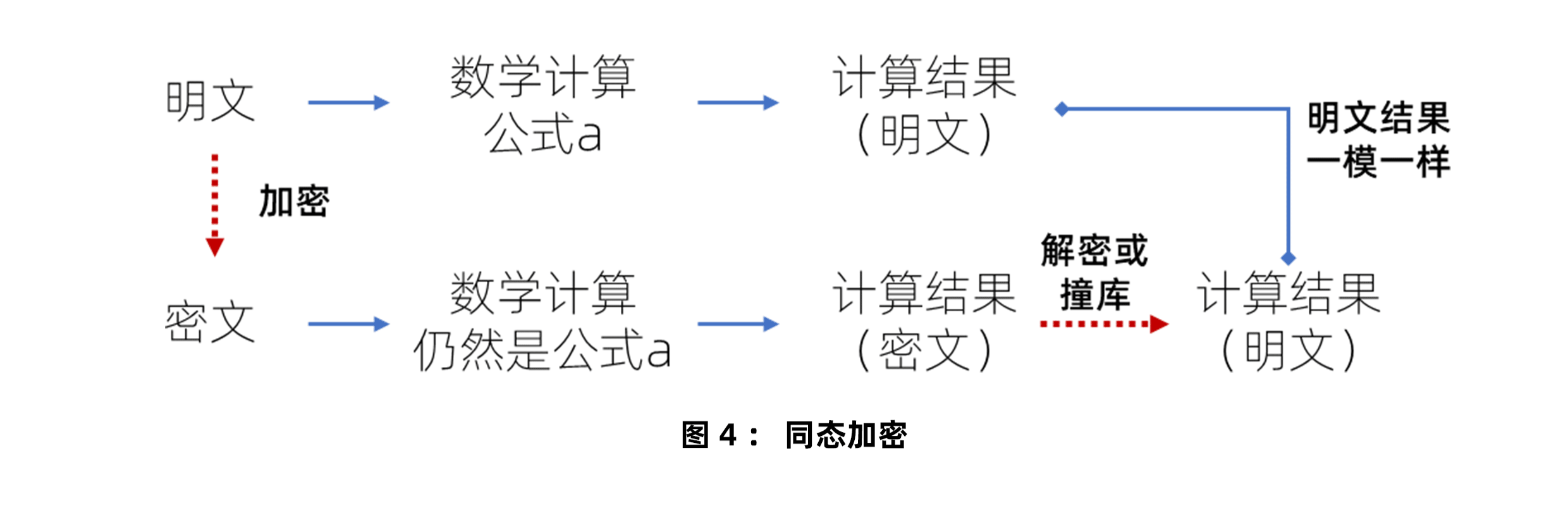
这样,广告主A没有暴露自己真正的消费者ID;媒体B也没有透露自己这些ID背后的属性;第三方C,帮助A和B完成了数据匹配,也计算出A消费者的共性特征,却也不知道这些特征具体是什么。只要C信守诚信,不泄露A交给他的加密的消费者ID,那么整个过程,就是相当安全的。
这就是隐私计算在数字营销上的一个非常典型且重要的应用。
—对交集ID进行保密的进一步优化—
基于可信硬件技术的安全屋
上面的“匿踪安全求交”需要加入很多“噪声”,同时对第三方的计算能力的要求很高。而且,还要确保第三方是诚实可信的。因此,在实践中,采用这种方法并不多。大部分时候,广告主和媒体都怕麻烦,媒体会直接在自己的服务器内辟出一个所谓的“安全屋”,然后让这个安全屋扮演上面第三方C的角色,发挥安全求交或是逆踪求交的作用。
这是目前最常见的实现方式,但谈不上小标题所说的优化,只能算是简化。这种简化,多多少少有点“自欺欺人”的味道。
当然,这种方法也不能说一无是处,媒体会强调,广告主的数据会在“可信硬件技术”之下被隔离保护起来,对广告主数据的操作,也是在这些硬件内进行的,并不会被泄露到这些硬件之外。
可信硬件技术,也在行业中被俗称为“数据安全岛”。
可信硬件技术主要解决下面的问题:
1. 数据独立(data separation):存储在某个分区中的数据不能被其他的分区读取或篡改。也就是说,广告主用于安全求交的ID,是不会被放到除可信硬件之外的地方的。
2. 时间隔离(temporal separation):公共资源区域中的数据不会泄露任意分区中的数据信息。计算资源,例如CPU,也有专门隔离的时间切片,来处理可信硬件中的数据。
3. 信息流控制(Control of information flow):除非有特殊的授权,否则各个分区之间不能进行通信。
4. 故障隔离(Fault isolation):一个分区中的安全性漏洞不能传播到其他分区。如果媒体严格采用可信硬件技术及管理,确实能够确保广告主提供的ID不被挪作他用。当然了,媒体是不是都能严格自律,我们可以看他们获得的执行标准的认证,比如《信息安全技术 可信执行环境服务规范》认证之类。不过认证这东西也不能100%全信,具体哪个媒体合格,哪个媒体不合格,就不在本文讨论的范围了。
全匿名下的安全求交(尚无定论)
上面的方法,对那些“较真”的广告主而言,可能是不可接受的。有些广告主,一定要求自己上传的ID不能被媒体知晓,那怕是加密后,并且媒体保证只用这些ID做撞库也不行。因此,他们迫切需要知道,是否有比“匿踪安全求交”更优化的方法解决这个问题。
目前,隐私计算的技术解决方案提供商可能已经找到了解法。这个解法,颇有些“釜底抽薪”的味道。简单讲,任何求交的过程,都必然会导致交集ID被求交的双方共同掌握(安全求交),或是被第三方掌握(匿踪安全求交)。那么,如果能够不做求交,就实现跟求交一样的效果,把广告主ID和媒体ID匹配的用户的属性直接计算出来,就不存在广告主的消费者ID被媒体知晓的情况了。
在2022年的一个新闻稿中,某个数据科技公司提到,他们的技术能够:“无需安全求交、不泄露交集ID、在全匿名数据集下进行联邦学习的技术难题,真正符合《数据安全法》和《个人信息保护法》的要求,进一步加强了用户数据安全和隐私保护。”
真的可以吗?我的客户和我见过的媒体都还没有采用,所以,我暂时还不能给出肯定的回答。但看到这个消息,至少让我觉得这个方向是有可能的。
ID求交(撞库)和可信硬件环境下的数字营销应用场景
广告主的消费者ID和媒体的用户的ID打通,本质上就是广告主私域用户的ID,和媒体的公域人群的ID的打通。一旦打通,很多数字营销的应用就变得可能。
应用一:Retargeting
Retargeting:广告主把那些在自己的私域中留下了各种行为和痕迹,但却没有实现最终转化的人的ID收集起来,然后把这些ID跟媒体的ID做安全求交,之后在媒体上给这些人投放定向广告。比如,某次大促,广告主A花了一个亿,引流到自己的私域小程序上,并获得了1000万个OpenID。然后,这1000万个OpenID中,有100万个发生了购买行为,剩下900万个没有购买。于是,广告主A又找腾讯,把这900万OpenID跟腾讯广告做安全求交,随之对这900万人进行定向的朋友圈广告投放。
应用二:Look-alike
跟Retargeting其实本质没有什么区别,只是多了一个步骤,即look-alike的步骤。还是上面那个例子,广告主A觉得对900万个没有购买的投放一次广告,人数有点少。于是就找腾讯广告说,我跟你安全求交后,请你帮我找到跟这100万购买人群类似的更多的人。于是腾讯广告基于这100万购买人群的共性特征,帮助广告主A找到了3000万个跟这100万人类似的人。随之对这3900万(3000万look-alike的人,加上900万retargeting的人)人进行广告投放。
应用三:基于一方、二方数据的联合人群圈选
这个是一个非常有意思的应用,是目前比较高端的应用。媒体可能只对部分大型广告主开放该功能。具体实现如下:
- 广告主将自己的消费者ID,以及每个ID对应的属性标签,在加密后,上传到媒体提供的可信硬件环境中。
- 媒体与这些ID进行安全求交。
- 求交之后,能够匹配到的ID,媒体也把这些ID对应的媒体端所拥有的属性数据,上传到该硬件环境中。
- 此时,这个硬件环境中,也就是数据安全岛中,就集合了交集ID,以及每个ID所对应的广告主的一方属性标签,和媒体的二方属性标签。
- 媒体基于这些ID和属性标签,以及基于这个可信硬件环境,为广告主提供一个圈选人群的界面。广告主在这个界面中,根据自己的需求,基于一方、二方的属性标签,进行人群圈选。比如,广告主A,跟媒体通过安全求交,匹配了1000万人。这1000万人,广告主自己的标签是过去一年内的购物数据和私域内的互动行为数据。而媒体端,则是这1000万人的社会属性和兴趣爱好数据。基于联合人群圈选的解决方案,广告主A可以选择,在过去3个月内购买了某类商品,且兴趣爱好是旅游的一线城市的20-30岁的女生。
- 圈选之后,媒体基于圈选结果得到的ID,进行广告投放,或是按照广告主A的要求做其他营销触达。或者,广告主也可以先基于自己的一方数据标签,圈选出人群,然后再看这些人群的二方属性是什么。从而更好地洞察自有消费者。比如,广告主A基于自己的一方数据,圈选出3个月内购买某类商品的人群,然后再在这个界面上要求媒体对这些做画像。媒体会提供这些人的二方属性的统计报告。
应用四:数据下发
所谓数据下发,是指媒体基于ID求交之后,将个体级别的数据传输给媒体。最典型的,就是“会员通”。
广告主将自己的会员ID加密后,上传给电商平台提供的“会员通”服务指定的可信硬件环境中(例如,阿里的聚石塔、京东的云鼎),ID在这里进行求交。求交之后能匹配上的ID的会员相关的数据,会传输给广告主。
应用五:Leads打分或决策判断
指在ID求交之后,第二方或者第三方为广告主提供是否应该为该ID进行某项营销行为的判断决策。比如,汽车广告主,将收集到的线索(leads)ID,通过安全求交的方法与运营商的数据相匹配。匹配后,运营商提供一个线索价值的打分返回给广告主。运营商为什么能做这样的事情,在这篇文章就不介绍了,如果感兴趣,欢迎上我的线下课《数据化增长:数据驱动的新数字营销》(点击查看具体课程介绍)。
安全求交之外的隐私计算应用
安全求交并不是隐私计算在数字营销中的唯一应用。我们前面讲过,安全求交本质上是“纵向联邦学习”。同样,“横向联邦学习”在数字营销中也有应用。
比如,我们如果有1000万个汽车购买者的私域数据样本,就能计算出,购车人在私域中做出的哪些行为(或行为的组合),就意味着他们要买车了。这个计算的结果,就是“购车预测模型”。
但可惜,每个汽车主机厂最多的样本也只有200万个。于是多个主机厂联合起来,他们不分享任何的ID给彼此(不做安全求交),而是各自基于自己的样本先计算一个“粗糙的”购车预测模型。然后各自把自己计算的模型结果上传到一个第三方,第三方基于这些车厂的模型,整合出一个新的模型。并把这个新的模型下发给各个主机厂,再次做计算,以优化这个模型的“梯度”。
至于什么是梯度,就不解释了,太技术。你可以简单理解为,就是对这个模型里面的参数什么的进行进一步优化。
这样的过程多来几遍,直到这个模型靠谱了,就能够给每个车企使用了。
你看,每个车企没有把自己的任何样本公开出去,却都得到了靠谱的购车预测模型。
所谓横向联邦学习,这里的横向,就是指,参与计算的各方,他们拥有的样本的ID并不相同,但是这些ID的属性类型是相同的,比如购买者都有在私域中的各种同样的行为类型(查看车型、查看购车金融、询问客服之类的,每个车企的私域都有这些相同的交互功能)、同样的社会属性类型等。而纵向联邦学习,则是样本的ID相同,而ID背后的属性不同。
讲到这里,终于把我想讲的基本上讲完了。不过,还有一些问题我没有能在这里进一步阐述,比如,这些应用场景具体起到什么作用,对不同行业的意义是什么,又如,隐私计算在数字营销中的合法合规性问题。这些内容,就不再写在回答中了,字数不够。大家听我的大课堂了解。
2)CDP导入非会员数据的应用场景有哪些?
Question:
我理解非会员只有订单的数据,只能看到非会员的订单维度,渠道/交易/购买产品3点的分析,而且数据不像会员数据可以无法去重,也没有性别/年龄/兴趣爱好等个人画像(没有key值和三方标签匹配)
CDP有比较大的一个场景就是应对非会员的。CDP里面的C,是Customer,但实际上跟CRM的C的Customer真不一样。CRM基本上还是会员,但是CDP的C,其实更是Consumer。
CDP的Consumer,也不是仅仅指购买了你的商品的才叫consumer(更不是必须成为会员)。这里的consumer,是指在你能获取数据的数字触点上所有留下数据的消费者(用户),无论他是否买了你的产品。
所以,CDP的非会员数据的应用场景,是非常广泛的。
现在,回到你的问题的正题上。
CDP导入非会员数据。既然是非会员,那么ID可能不是实名信息的可能性大。也就是可能没拿到电话号码。
不过,不妨碍,只要是数字触点,尤其是私域数字触点,都能有ID,例如,微信生态的OpenID和UnionID,网站端有cookie,APP端有OAID,DeviceID,IDFA,以及CAID……
这些数据背后,全部都可以拿这些用户的行为信息。
基于ID和行为,最常见的应用场景,就是在对应的触点生态内进行的消费者运营。其中以微信私域的运营最为常见。
比如,在小程序中,用户只要进入你的小程序,你就能拿到用户的openID,你可以用这些OpenID及背后用户的各种行为,进行人群细分。然后可以在微信朋友圈中基于细分人群追投朋友圈广告。同样,基于这些OpenID,还可以在腾讯广告生态中的其他广告上做圈选投放。
没错,虽然没有年龄性别等个人画像,但是有这些用户的行为数据。此外,这些数据还是可以上传到对应的CDP(比如腾讯广告如翼)去做人群画像的。
另外,在针对性的内容发送和推荐上,这些数据也很有价值。例如,APP端,这些数据可以用来做千人千面的展示。
你的问题中举出的非会员的例子是订单数据。所以,我猜测你更希望看到的是电商相关的场景。在电商端,如果有订单,那么我认为就拿到电话号码了。虽然不是会员,电话号码+订单信息,作为营销的关键数据,价值还是很大的。例如,做look-alike投放,就特别需要这些数据;目前的很多效果类投放,尤其是竞价投放,这些数据对提升投放ROI的价值也很大。
此外,只要有订单数据,其中电话号码又可以上传媒体端DMP,给你做人群画像(个体画像现在不可以了),这样实际上还是可以看到性别年龄兴趣等大致的情况的。
而且电话号码是一个关键性的ID,可以粘合多个触点上同一个用户的数据,这样就能整合消费者的数据。我个人其实不是特别在意是否消费者一定要成为会员,但却总是建议我的客户一定要拿到电话号码。目的真不是为了发个短信,更不是为了打骚扰电话。而是能通过电话号码做数据的整合。
也就是说,虽然不是会员,但是有电话号码的价值很大。
我在这个知识星球里,前面有录视频,介绍手上有电话号码的时候,应该怎么做营销,你可以往前翻回去,看一看。
当然,能成为你的会员,是最理想的状态。
05 加入知识星球
