

我的第25期大课堂在上海落下帷幕,在这期大课堂中,我第一次将《个人信息保护法》下数字营销的变化以及应对加入其中,这个部分也引发了同学们的深度关注和巨大的兴趣。
这促成了这篇文章。
01 恐慌?并无必要
大家最关心的问题,是《个保法》实施之后,是否很多数据都不能用了。
答案是,确实很多过去常用的数据,现在不能随便用了。
一家国际美妆品牌巨头,在过去若干年积累了大量的设备ID及属性数据,现在,需要重新获得授权才能应用这些数据。
(法不溯及既往,过去若干年获取这些数据的行为本身不涉及违反《个保法》,但是法律颁布之后应用这些数据,则仍在《个保法》的约束之下,是需要获得消费者的知情同意的。)
重新授权?看起来这是不可能完成的任务,毕竟,当时获得数据的时候,都谈不上授权。
这几乎意味着,这些数据已经无法再被使用。而无数类似的数据都不能再使用的结果,似乎是非常灾难性的,这让人感到不寒而栗。
确实恐慌。
但沉下心来想一想,恐慌来自于,过去粗放(甚至粗暴)获取数据的方法不再可行,一时间又找不到可替代的方法。
有什么可恐慌呢?
车到山前必有路,船到桥头自然直。粗暴的方法行不通,是因为思维的出发点就是错误的。相比起过往的野蛮生长,现在是更加规范,有法可依的时代,无论从什么角度看,当下的时代都是“难而正确”的,拒绝投机和抢跑,而是重新站在同一起跑线上,寻求合法合规发展,这无疑是一件更好的事情。
无需恐慌,但真的需要改变。
02 数据应用的改变,从获取开始
要注意,数据的应用与数据的获取密切相关,数据获取的方式决定了数据如何应用。
数据的获取,当然要遵循“知情同意”原则。也就是说,你若要用数据,需要让你的用户或者你的消费者知道你收集他什么数据,以及怎么样利用这些数据。
但有几点很需要注意。
第一,有些场合(或者场景),你没有机会(或途径)对消费者进行告知,也就无法获取他的知情同意。比如,WIFI探针这种方式为什么很难获得合法性,因为WIFI探针没有可以获取消费者知情同意的界面。
第二,即使你有机会告知用户你要获得他的数据,并且让他同意,也并不意味着你可以任意获取他的数据。这涉及到《个保法》所规定的“两个最小原则”——影响最小、范围最小。没必要收集的数据不能随便收集。
(国家规定了不同网络应用收集数据的必要范围,大家可以查阅《常见类型移动互联网应用程序必要个人信息范围规定》。)
当然,什么算是“必要的”,是可以设计的:你为你的数字触点增加了吸引用户的额外功能,这些功能又必须要基于用户的某些特定数据才能被使用,这时,你有机会突破你本应该收集的数据范围。不过,这时需要注意,你可能需要在用户使用这些功能的时候,获得他们额外的单独的数据授权同意。这一点是我在下面要单独讲。
第三,在部分特殊情形下,你需要在一揽子数据收集协议(就是第一次用某个app或者小程序的时候让你同意的那个隐私协议)之外,单独再征得用户的同意。例如,超过国家规定的必要数据收集范围的数据收集,需要征得用户的单独同意。将数据提供给第三方(这也是数据应用的常见情形),也需要获得单独同意。
考虑到“将数据提供给第三方”这种情形常常发生在广告主获取外部数据的场景中,这使得广告主可获得数据的来源必然发生变化。
例如,媒体将device ID(设备ID)回传给广告主,这实际上属于将数据提供给第三方(此时的第三方是广告主)的情形,这将导致媒体必须额外征得用户的单独同意方可实现。这,意味着广告主能够获得的媒体回传的device ID将完全行不通。
(媒体,在数据安全和合规上,是最为谨小慎微的。你懂的。)
又如,广告主从第三方获得数据,也会变得很困难。第三方的数据,即使是通过正确的用户的授权而获得,在提供给广告主的时候,也需要重新征得用户的单独同意,这在实际操作中,基本没有可能性。
03 构建企业自有数据体系要有新策略
从数据获取的新情况可以看出,《个保法》的核心合法性基础,是“知情同意”。
企业要拥有自己的数据,无法绕过知情同意这个“坎”。
从这个角度看,企业必须拥有一个与消费者对话的界面——无论是自己构建私域,还是借助巨头平台提供的工具和技术,构建自己的小天地。
显然,构建私域是收集数据最理想的方法。
所谓私域,从技术性上讲,永远只有一个标准来衡量是否是真正的私域。那就是,在这个域中,是否允许我(企业)添加自己的监测代码(或监测SDK)。
有自己的私域,能够让用户知情,也能有很大的机会获得他们的授权同意。有自己的私域,也能够通过监测获得用户的数据。微信的小程序和微信的服务号就是最典型的例子。
毫无疑问,《个保法》进一步提升了私域的重要性。
不过,构建私域不是唯一的策略。
私域,一般而言,是为最核心的忠诚用户准备的,但不是所有的用户都愿意进入你的私域。这时,我们需要向外圈扩展,获得更多用户的数据。
因此,一个也同时变得更加重要的策略是,借助巨头提供的技术和工具,在它们的平台中构建自己的一个小天地,在这个小天地中,以合理合法途径获得用户授权,进而获得数据。
比如,电商的“会员通”,或是企业微信,或是各种企业号。这些小天地也是企业可以自行接触用户的空间,但或许只能被称为“半私域”。
有一点很重要,你需要辨识这些“半私域”上的知情同意的授权,究竟是授权给这个平台的,还是授权给你的。
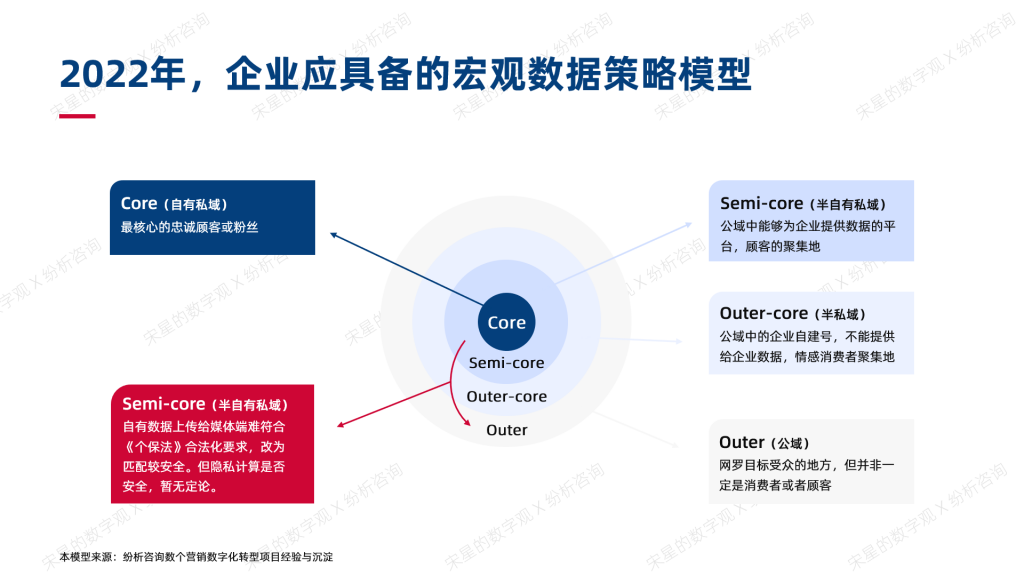
以电商的会员通为例,其中的消费者的相关数据应该是授权给企业的,因此,这些数据应该被企业所有,这种情况下,数据可以被回传到企业自己的CDP或是CRM中。
不过,与自有私域不同,“半私域”的数据虽然授权给了企业,但是授权的数据范围有限:电商的会员通,基本上是会员基础信息和订单信息;微信的数据,则主要是通过API能够回传的部分,例如OpenID、UnionID和部分的行为。这些数据是用户数据的部分,比不了在自有私域上能获取几乎全部用户的行为数据。
另一类“半私域”,如抖音的企业号和抖音的企业粉丝群,小红书的企业号等,用户的知情同意并不是授权给企业的,因此,这些数据无法被回传,也基本不可能被用在其他(非该平台内)的场景或者平台中。
这些触点平台上产生的数据,只能算是“别人(媒体)的数据”,而难以成为自有的数据资产。
04 不是自有数据,并不是不可被利用
尽管“别人的数据”听起来很悲观,但事实并不如此。拥有数据并不是利用数据的必要条件。你可以在不拥有这些数据的情况下使用数据。
巨头媒体平台提供相关的工具,并且在获得消费者的知情同意的前提下,将这些工具和数据给企业使用。
媒体获得了用户的知情同意这一点很重要,这让企业基本无需为使用数据的合法性担心,而且也无需企业做额外的工作去获得消费者的知情同意。
数据应用方面:在你的“半私域”中,这些工具帮助你圈定你的粉丝。在投放中,这些工具帮助实现目标人群的圈选,也提供对目标人群、行业以及内容的洞察。你无法真正看到这些数据的每一个条目,但在投放上的应用却极为成熟。
不过,对这类数据的应用有一个很大的局限性,那就是只能应用在这个媒体巨头的生态内,且大部分围绕广告投放(洞察本质上也是为了投放)。
所以,这些围墙花园平台里的数据(数据只能按照平台提供的方式被使用,且无法看到和获取到这些数据),极少用于精细化运营,而更偏重于更广泛的目标人群的触达。典型的数据产品,如腾讯广告的知数。
讲到这里,你其实已经可以发现一个很重要的事实:《个保法》实施之后,企业对数字营销所需要的数据资产的获取与应用,及其对应的策略,必然是有层次,有区分的。
如下所示。
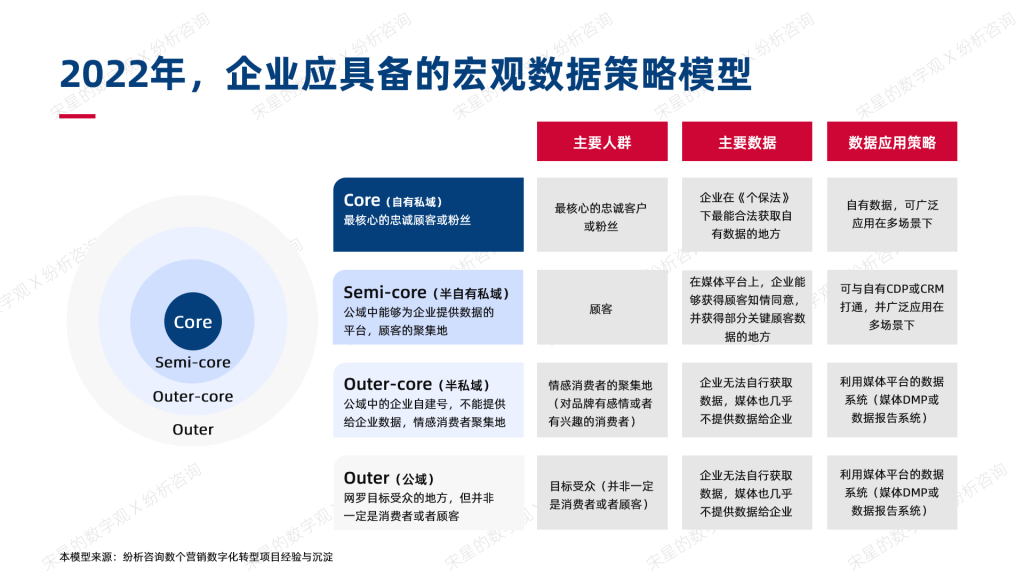
05 从上传数据转变为匹配数据
《个保法》实施之后,另一个极为值得注意的领域,是企业如何在媒体平台中应用自己的一方数据的问题。
过去,方法是上传数据给媒体平台。
《个保法》下,这种方式属于“向第三方提供数据”(企业把数据提供给媒体平台)的情形,需要征得消费者的单独同意。这种方式难度太大,需要企业需要获得用户的授权,同意把数据提供给媒体方(此时媒体=第三方)。
但,企业的自有数据,无论是作为广告投放所用的监督学习的正样本,还是让媒体帮助实现数据补强(通常是做洞察),都需要跟媒体平台发生交互。
因此,数据的应用,要改“上传”为“匹配”。
所谓匹配,是企业将自己的数据加密后,与同样经过加密的媒体的数据进行匹配(仍然需要依靠ID)。匹配之后,媒体不会将任何个人信息数据回传给企业,而是用于广告人群的圈选,或是提供无法识别出个人身份的洞察报告。
“匹配”没有发生实际的数据转移,因此不属于“向第三方提供数据”的情形,但应该属于“共同处理”数据的情形,在这种方式,必须要找一个靠谱的媒体平台完成。原因是,在共同处理的情形下,任何一方导致的个人信息权利侵权,都会导致另一方的连带责任。
在这个角度上,对于企业而言,找一个靠谱的媒体平台非常重要,(相对来说,腾讯、头条这样的头部媒体平台在目前更值得信任,它们已经具备相对成熟的数据安全保障体系。)因为这不仅仅是自有数据能否安全(不被媒体或者第三方获取),更涉及到在法律层面上的安全。
在一些新的数据技术的帮助下,“匹配”可以以更高级的形式进行,即“隐私计算”。“隐私计算”或许可以为企业提供个体级别的数据标签,从而实现个体级别的数据补强(与洞察不同,洞察的数据补强是以报告呈现的,只是一个结果)。
背后的原理有同态加密,或是联邦学习(以纵向联邦学习和联邦迁移学习的方法为主)。这些方法能保证在整个过程中参与方都不知道另一方的数据和特征,却又能利用对方的数据,进行模型训练。在模型训练结束后各参与方只得到自己侧的模型参数(个体的新的属性数据)。这样,在彼此都不泄露自己数据的情形下,广告主的数据得到了补强。
但是,这个方法属于《个保法》下的“向第三方提供数据”还是“共同处理”尚无定论,因此,也就很难确定是否存在更大的风险。不过,总体而言,隐私计算是目前看来极(zui)有前途的一种解决方案,用技术手段来实现数据为用户自己所用,但不涉及数据泄露和交换的问题。很多企业也正在探索隐私计算等方案,腾讯发表了隐私计算白皮书;腾讯,字节、阿里等公司也有隐私计算等方案的技术研究。不再赘述。
06 写在最后
《个保法》对企业获取和应用数据提出了新的要求。传统的粗放的数据策略和用法需要革新,但这并不意味着再无数据可用。
企业对于数据的策略的一个重要的革新,是在《个保法》的约束下,对数据要具有分层次地收集和应用。
另一方面,我们对数据的态度仍然需要乐观。技术上,确保个人信息完全不会泄露且完全合法的数据应用方式一定会出现,例如不断改进的隐私计算技术。政策上,国家一定会鼓励数据的应用,而不是压制。
用习大大的讲话做结尾:“大数据是工业社会的‘自由’资源,谁掌握了数据,谁就掌握了主动权。”
祝愿你早日获得这个主动权。