

总结与更新经典模型的文章,我是每一年都一定要写一篇的。
工具总是不断推陈出新,增加(或者打补丁)各种功能,但思维模型和分析方法,却隽永而美好。更何况,有了各种模型,才幻化出各种各样的工具。
所以,学习模型和方法才是真正事半功倍的好办法。
不过,与以往我的文章不同,这篇文章不纠结于细节(不然又是几万字的大文章,大家看着也累)。如果你希望更深入了解具体模型,我会提供链接,大家可以进一步阅读。
另外,一些非常理论化的模型,比如AARRR,AAAAA(5A),AIPL模型,因为更多是一种思维,而不是方法,没有被我总结在此列。如果大家对这些模型感兴趣,百度搜索便知。
那,现在便开始我认为重要的2019年的更新版模型总结吧!
模型一:Engagement Index模型
Engagement Index模型的思维并不复杂,即权重化部分甚至所有的用户交互行为。
讲一个最理想最极端的例子(但这样的例子有助于大家理解),如果你认为最终的一个转化价值1000分的话,那么转化之前的用户的行为可以按照与转化发生的比例“打分”。例如,每发生1次转化,就需要看商品介绍页面100次,那么查看商品介绍页的行为每发生一次,就值10分。
这是手工计算的Engagement Index。放在AI这么热门的今天,Engagement Index有可能就是机器来计算了,计算的方式,跟我们后面要讲到的归因模型比较类似。
大家对于Engagement Index模型可能还比较陌生,但对于它的应用场景你肯定不会觉得陌生。
今天,无论是给用户打标签(尤其是CDP或者DMP给用户打标签)所用的方法,还是CRM给销售线索打分,又或是评价一个流量或者人群的质量,无一不是基于这个模型或是以这个模型作为思想。也正因此,把它放在诸多经典模型的首位我自认为并不偏颇。
比如,我非常喜欢的一款全渠道营销管理与自动化工具Marketin——可能了解的朋友同样不多,但这个产自中国的工具制作的非常良心且用心——的用户标记及销售线索打分的功能,就是基于这个模型。
关于Engagement和Engagement Index的解释,可以看我很多年前写的文章:网络营销效果衡量的核心指标及我们用什么样的逻辑思考(2);网络营销效果衡量的核心指标及我们用什么样的逻辑思考(3);网站分析的最基本度量(8)——Engagement
模型二:Engagement-ROI模型
从Engagement Index可以引出另外一个同样极为重要的模型:Engagement-ROI模型。
这个由两个指标构建的模型是我们解决流量质量和人群质量分析中诸多问题的开端。我们通常会构建一个四象限的模型来进行分析:
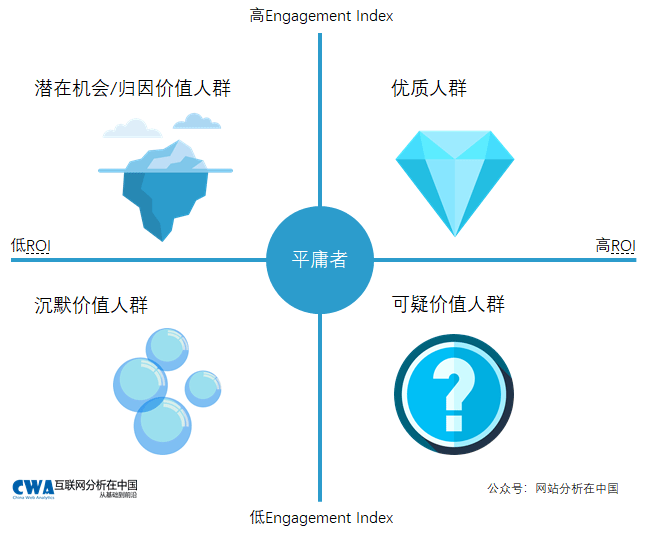
理解Engagement-ROI模型并不困难,它描述了人群的行为(兴趣)和最终变现之间的最直接关系。高兴趣而低变现(上图的第二象限)和低兴趣而高变现(上图的第四象限)都值得我们进一步挖掘。尤其是高兴趣低变现的情况,可能蕴含着未被发掘的价值或潜在机会。
这个模型对于拥有较复杂流量/人群构成的企业而言,极有价值。
关于这个模型,我没有写过相关文章。但在公开课上会详细介绍。
模型三:以人为核心的转化漏斗模型
转化漏斗大家绝对都不陌生。但转化漏斗模型本身仍然在进化。
主要的进化是从以流量为核心的转化漏斗,进一步扩展为以人为核心的转化漏斗。
这并不意味着以流量为核心的转化漏斗不再重要,对于较为需要在段时间周期内实现转化的生意,构建以流量为核心的转化漏斗是优化的必用模型。
但以人为核心的转化漏斗的区别在于,考虑到今天数字世界的极为膨胀和碎片化的趋势,不同触点(关于什么是触点,请看我的这篇文章:DMP 101之一:DMP的本质是什么?)的用户是同一个人的情况非常普遍,实现以人为核心的转化追踪和分析就更加重要了。
下面这个图很好的解释了以人为核心的转化漏斗模型。数据分析也因此比以流量为核心的转化漏斗要复杂——并不是因为计算更复杂,而是数据的来源更多,且时间周期更长。
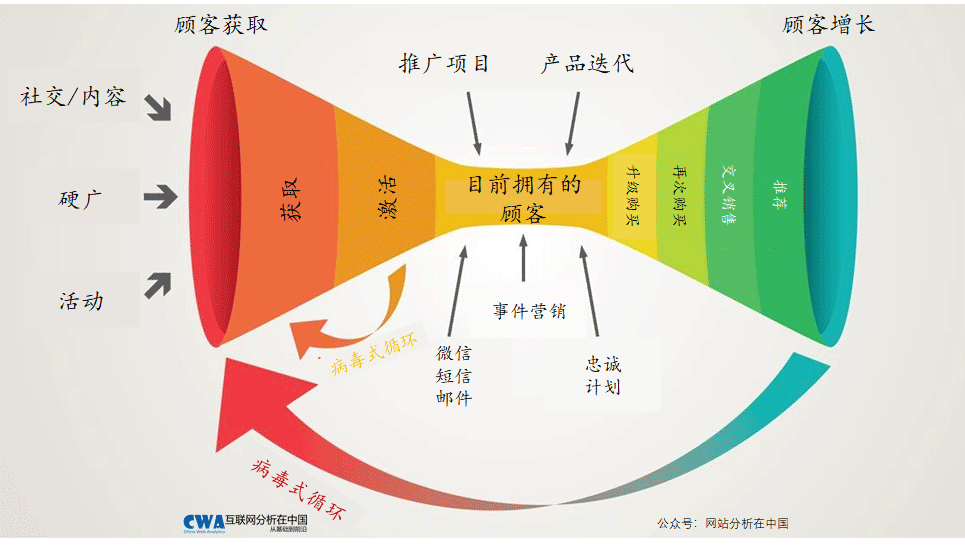
这个模型的实际使用功能常常由DMP或CDP实现,普通用户行为工具较难完成相关数据的抓取,也就很难构建模型。
这个模型跟后面马上要提到的归因模型有关联,但也有区别。归因主要是以渠道和触点为维度,描述各种转化路径的构型,分析渠道与触点对最终转化的贡献;而以人为核心的转化漏斗,则是用于分析预置步骤的转化过程。相对而言,归因模型更加复杂。
关于转化漏斗的基础知识,可以看这两篇文章:互联网运营数据分析必须掌握的十个经典方法,数据驱动的电商销售转化提升的方案与实践——跨境电商的一个真实案例。
模型四:MOT、归因以及消费者旅程模型
严格来讲,这是三个模型。MOT模型用来表述消费者发生的关键性转变,归因模型则描述引发消费者关键转变的渠道或是场景,而消费者旅程则从更“普遍性”的角度描述同一消费者跨触点的行为。
MOT的意思是Moment of Truth,描述消费者被营销或者激发之后发生的行为变化的关键时点。
当进行营销活动的设计(campaign)以及监测这些campaign的效果时,我会特别推崇MOT模型。因为本质上,设计一个campaign,就是为了确保各种营销活动的“伏线”能够激发消费者兴趣及行为的转变。
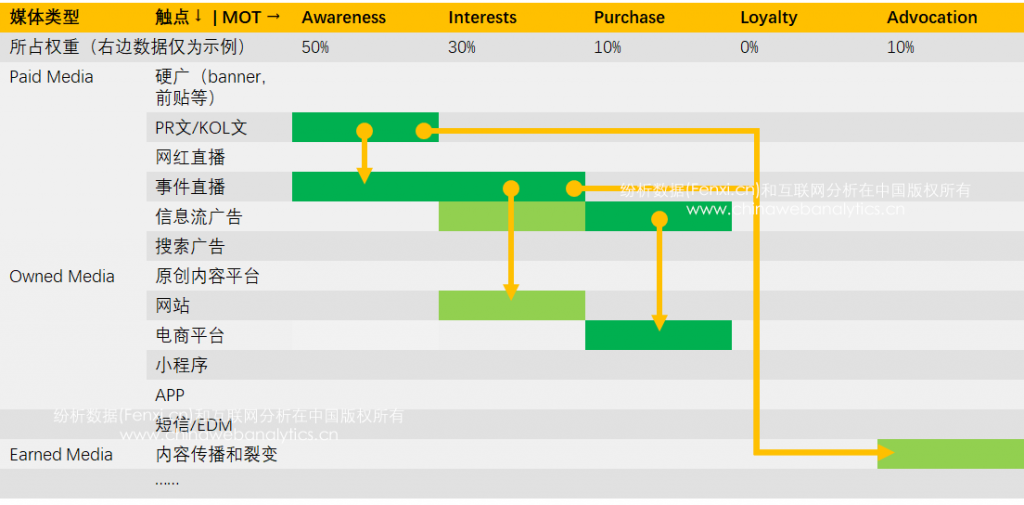
上图是MOT模型的一个典型示例。你可能一下子看不太懂,别担心,我稍作解释。
这个图的主旨是对campaign中消费者的旅程(customer journey)进行设计的“索引表”。任何一个campaign都有营销目标,因此上图第一行是AIPLA模型指导下的营销活动的常见的目标,并且第二行为每个单一目标打了权重,每个campaign的权重设置可能都是有区别的,毕竟不同campaign的偏重不同。
在这个总目标下,营销人再继续“编织”更细节的营销活动安排,比如,为了增加awareness(曝光度),做KOL的子campaign。图中的绿色格的深浅,表示了在每个环节资源投入的程度,颜色越深,投入资源越大,该项活动占有的权重也越大。
你肯定也注意到了黄色的箭头线,它代表了一次campaign中的各个具体活动(子campaign)之间的关联或者转化关系。设计转化关系对于campaign,尤其是品牌campaign尤为重要,因为品牌campaign的真实绩效数据更加难以获取,那么必然需要让消费者产生可以被量化的行为才能容易衡量campaign短期内的效果。不仅如此,黄色的箭头也描述了消费者即将发生的实际旅程。
在具体利用这个模型的时候,肯定还需要在每一个绿格中间填入更加细致的活动设计、数据指标及收集方法,以及执行方法等。
精细地应用MOT工具,能够极大程度帮助营销活动的执行与之后的数据分析。这也是为什么我一直强调,营销与运营的数据是提前规划才可能获得的,而不是依赖于某种技术或工具就能随时获得,尽管技术和工具必不可少,但提前规划更加重要。
那么,为什么要把MOT和归因等两个模型并列呢?
原因在于,MOT是归因模型和消费者旅程模型的基础,而归因模型(尤其是基于用户而不是基于流量的归因,但目前只能通过强用户ID实现)与消费者旅程模型则是用来定量化描述MOT和消费者旅程的。
归因模型解决两个问题:第一、对于一次成功的转化,各个渠道或触点各有多少的功劳;第二、描述各个渠道或触点对该转化进行贡献的先后关系甚至因果关系(但因果关系还需要人进行分析才可能得出)。对于归因的解释有非常多的文章,我会建议大家阅读iCDO(互联网数据官)上关于归因的专题:http://www.icdo.com.cn/?s=%E5%BD%92%E5%9B%A0。在我的大课堂上则有非常详细的讲解与应用案例。
而消费者旅程模型则是更加“泛化”的归因模型。归因模型仍然强调要发生最终的转化,因为归因二字,实际上是英文attribution(功劳归属)的意思,所以它的作用是回溯转化之前的渠道和触点。但消费者旅程模型则直接描述消费者在不同触点上的行为和先后发生的次序。你可以认为消费者旅程模型是流量的路径模型升级为“以人为核心”的“高级”版本。实现消费者旅程模型的最重要工具是DMP或者CDP。大家可以查看我DMP系列的文章:http://www.chinawebanalytics.cn/?s=dmp,有很多细致的解说。
MOT模型、归因、消费者旅程、转化漏斗,实际上都经历了从流量分析到人的分析的转变(如下面的引用所示)。
流量 –> 人
网站/app/小程序等单触点上的关键行为 –> MOT
基于流量转化的归因 –> 基于人转化的归因
流量路径 –> 消费者旅程
流量转化漏斗 –> 以人为核心的转化漏斗
这些转变的背后,是互联网产品进一步细分分化,和消费者进一步碎片化的必然结果。不过,坦率讲,以人为核心进行数据收集和分析,目前面临了很多尚未解决的问题,目前能收集到的数据范围很有限,数据质量则参差不齐。
模型五:细分模型及各种常用的细分场景
另一个最最重要的模型几乎贯穿我们所有工作的始终。当然,说它是一个模型并不妥当,它是一类思维方式的总称。这个模型当然是细分。
细分本身并无什么玄妙之处,我也无须解释。不过,常用的细分模型还是有一些典型的类别的,掌握如下这些(还包括太多太多我没有写进去的)常用的细分方式,对我们的工作有事半功倍之疗效。
1. 流量渠道细分——最常用的方式就是我们模型二:Engagement和ROI模型所用的方法。
2. 流量与落地页细分——对于分析流量和承接端的匹配那是超级有用。
3. 人群细分,尤其是注册与非注册人群——CDP、DMP的根本。而我本人,则喜欢对更显性的人群做细分,例如,已经注册和未注册人群的差异。
4. UI和内容的细分——用于辨识不同UI和内容对于人的行为的影响。常常用于分析和优化转化,尤其是微转化领域。
5. 行为细分——热图,下一步分析,参考我热图相关的文章:http://www.chinawebanalytics.cn/?s=%E7%83%AD%E5%9B%BE。
6. AB测试,本质上也是利用UI或者UX的差异,人为故意地建立行为的细分,并且AB测试已经不仅仅扩展到UX,随着人群细分能力和CEM相关技术的提升,现在已经可以做到针对不同的营销策略和执行进行AB测试。这样能对不同营销策略和执行进行AB测试的工具,例如我前面提到的Marketin。与前面讲的第4种的区别在于,这个是主动建立差异,而第4点是细分不同业已存在的UI或者内容。
细分极为重要,各种细分场景也多到数不清,而且很多其他模型本身就是一种细分,比如我们讲的转化漏斗和归因,就是对过程进行细分,比如后面讲用户忠诚和留存的cohort,就是对人群进行细分。善于进行细分是一种能力,体现了营销和运营工作的基本素质。
模型六:流量优先级模型
媒体的eCPM决定了流量优先级,而流量优先级又进一步决定了你能获得的流量质量的好坏。因此,进行引流操作,必须理解这一模型和背后的原理。
这个模型的含义是任何媒体都不会将他们的各类广告资源视为同等重要,其重要性由eCPM决定。eCPM越高,媒体就会给予这类资源更高的优先级并寻求将之与更高优先级的广告主进行匹配。
高优先级的资源往往具有更好的质量。因此,反过来讲,如果广告主希望获得更高的优先级,那么在预算一定的情况下,应想办法让广告主的eCPM得以提升。
对于任何非CPM和CPD的广告资源,广告主提升媒体eCPM的好方法是提升CTR(对于CPC类广告),或是转化率(对于CPA类广告)。
媒体普遍采用的监督学习的机器学习方式,进一步强化了这种趋势。
具体内容可以参考这篇文章:质量得分的秘密——什么逻辑?如何优化?
模型七:用户忠诚与流失相关的模型
这个模型同样不是一个,而是一组,包含多个模型:留存曲线、cohort模型、RFM、流失预测模型等。
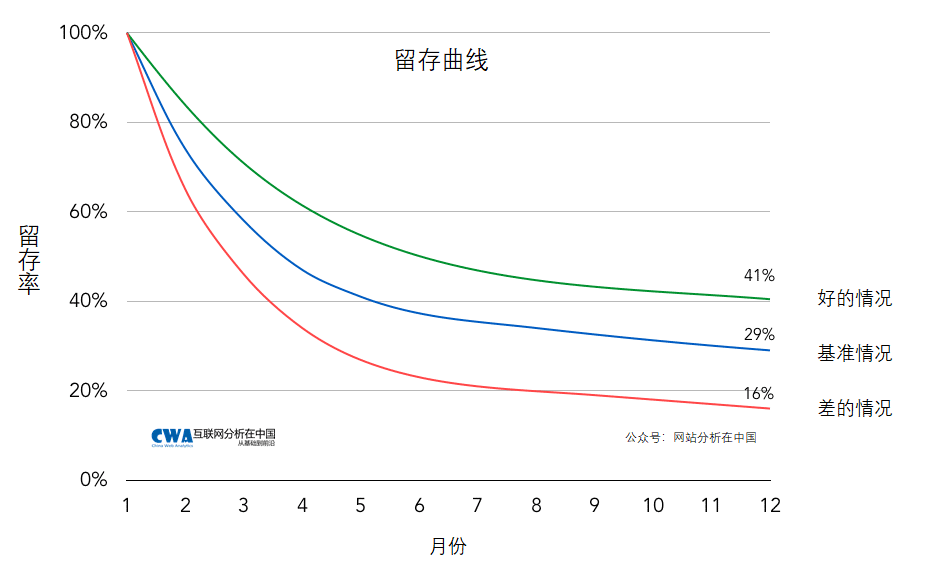
留存曲线是描述一个细分人群(通常用时间细分,或者用人群源细分),随着时间留存的情况。下面两个图,第一个是示意图,第二个则是具体真实数据例子中的图。留存曲线比较直观的展现了不同群体留存的情况,从而帮助我们分析什么属性或者什么原因能够有更好的留存。
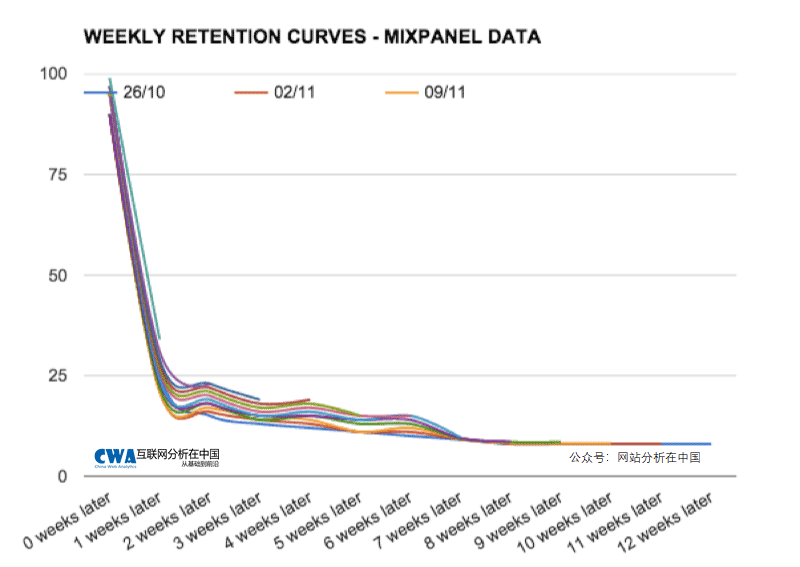
Cohort模型(同类群模型)则是留存曲线用具体的数字来表示,本质上跟留存曲线并无差异。下图就是一个典型的cohort分析图。
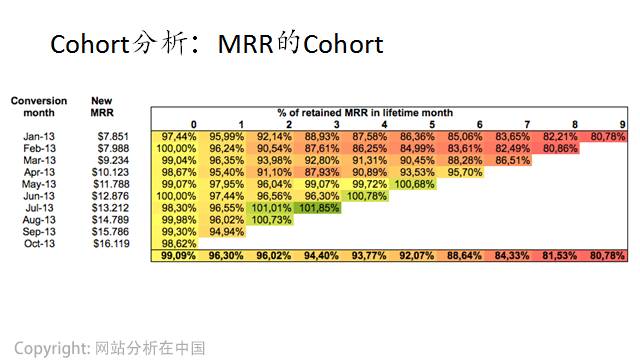
关于cohort分析,看我的这篇文章:互联网运营数据分析必须掌握的十个经典方法。
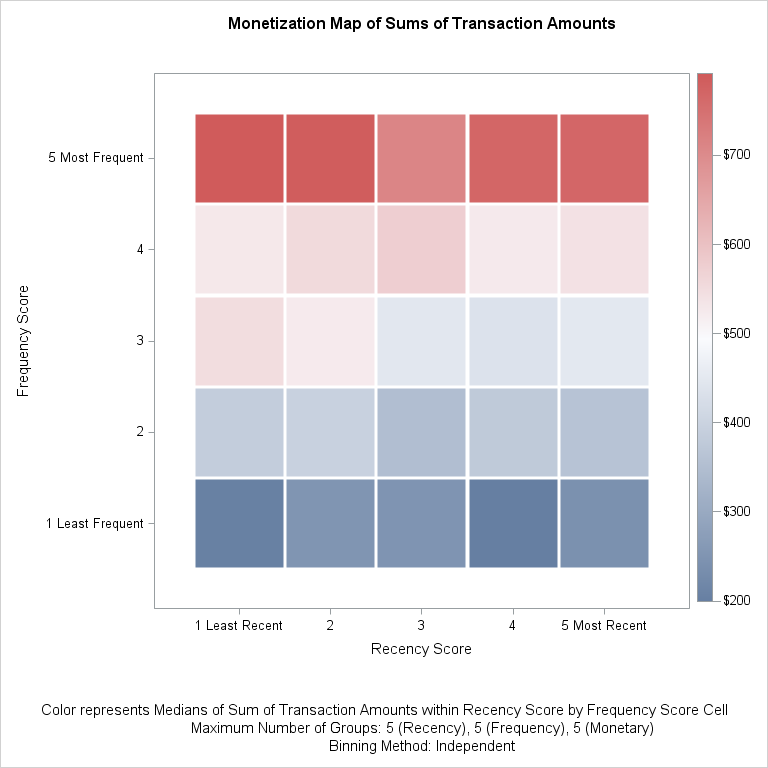
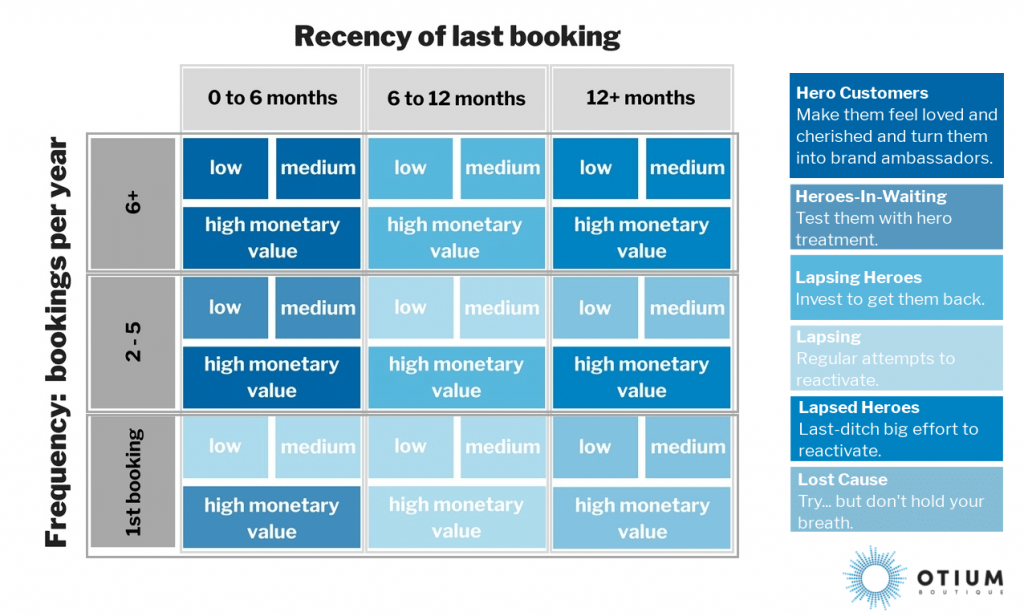
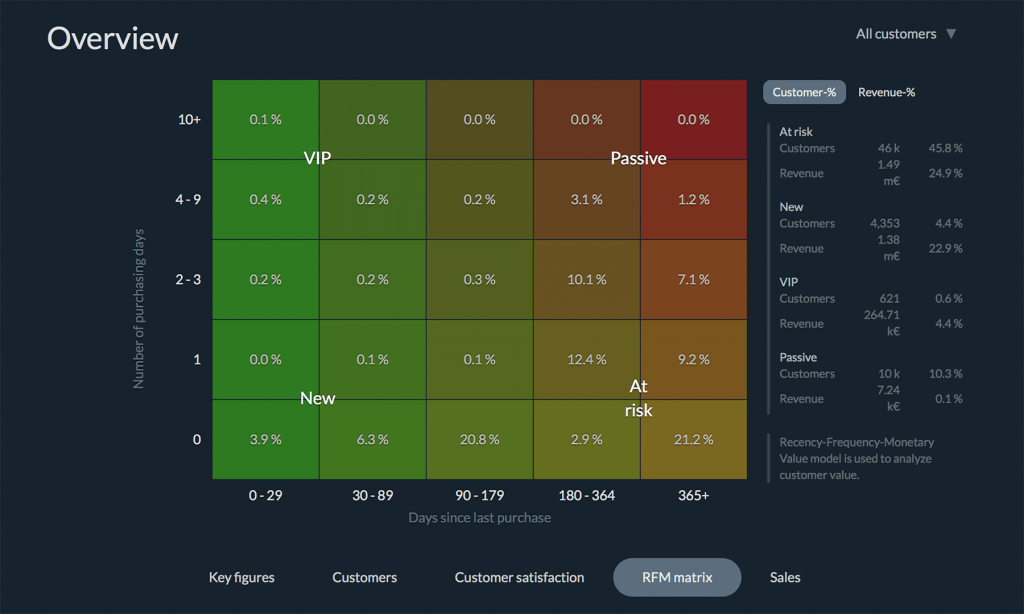
另外一个模型——RFM模型——是一个非常棒的模型,因为它基本上用excel就能完成模型的建立,但作用却非常巨大。
RFM用三个维度R(Recency,新近度)、F(Frequency,频次)、M(Monetary Value,现金价值)来衡量用户的价值。下面三个图都是很棒的分析,最后一个是输入数据后,工具直接实现的。这个工具感觉不错(我没用过)。
流失预测模型,是用历史流失发生的数据,训练数据模型,从而预测未来的流失,最常用的模型是决策树之类的数据挖掘方法。这个模型普遍应用于零售、游戏、高频次的互联网服务等。我的大课堂会介绍,不再赘言。
模型八:增长曲线
增长曲线是极为简单但重要的模型,它描述了增(减)的趋势。
例如,在搜索投放中,我们建立增长曲线观察一个核心类词的增衰趋势。
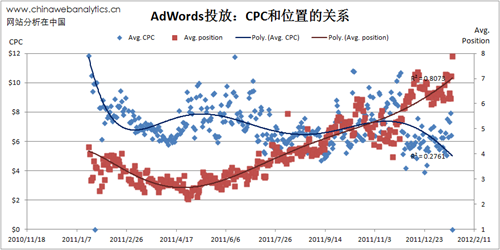
又如,我们用增长曲线发现不正常的增长(作弊)。
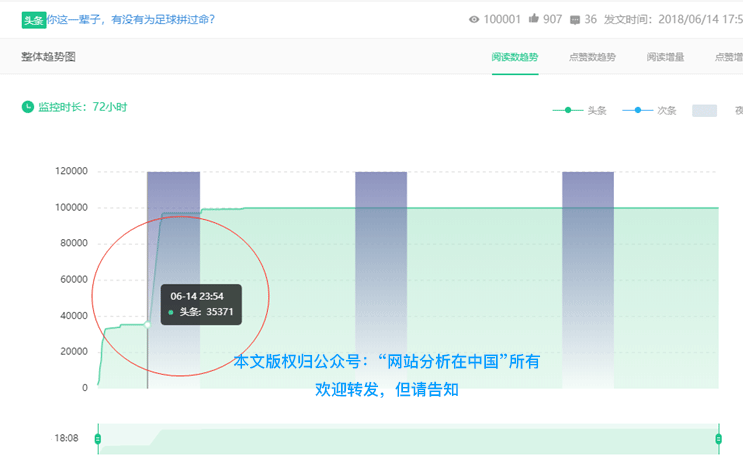
增长曲线模型最重要的不是曲线本身,而是解释曲线增减背后的原因或故事。
模型九:监督学习
监督学习前面已经提到了好几次,它是如此重要,事实上我们的很多人工智能本质上都是监督学习(当然也有别的机器学习的方法,但监督学习无疑是最基础最重要的)。
监督学习主要在今天的精准广告投放上发挥作用。例如高质量的DMP和CDP应该带有监督学习的模块或者能力。
监督学习依赖于更广范围和更高质量的数据。毫无疑问,今天以人为核心维度的数据收集为监督学习提供了更大的空间。
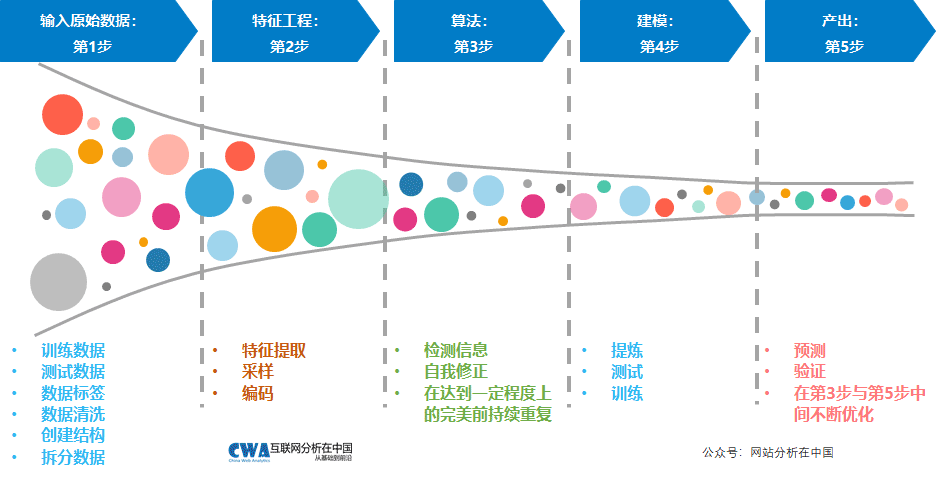
并不需要你学习如何创造监督学习,但显然理解它的逻辑很有意义。这篇文章可能能够帮助你:【万字长文】深度解读2018年互联网营销的新生态。
模型十:推荐模型
推荐模型基本上是今天互联网运营最常用的模型之一了。这个模型的价值在于提升用户体验,并且创造cross-sell和up-sell的机会。因此,它显然也是一个围绕人构建的模型。
推荐模型基于一些常用的推荐算法或算法的组合。
这些算法包括:协同过滤算法、逻辑回归、或者近似内容关联。机器学习同样用在推荐模型中。
协同过滤算法这个最为常见的算法,它的逻辑很容易理解,如下:
如下文字引用自:https://blog.csdn.net/fyq201749/article/details/81026950,作者:fyq201749
协同过滤算法(Collaborative Filtering, CF)是很常用的一种算法,在很多电商网站上都有用到。CF算法包括基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)。
基于用户的CF原理如下:
- 分析各个用户对item的评价(通过浏览记录、购买记录等);
- 依据用户对item的评价计算得出所有用户之间的相似度;
- 选出与当前用户最相似的N个用户;
- 将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。
行业中有大量的开源的推荐算法。不过,开源的推荐算法往往不够解决你的实际业务问题,因此,推荐算法需要做一定程度的定制或重构。
总结
这十个模型(事实上是15个具体的模型)并不能穷尽今天在互联网营销和运营上的全部常用数据方法。但我认为,理解当今的行业变化至关重要,在此此基础上再决定应该应用什么样的方法或者模型才更加现实。今天的行业变化正在从流量为中心变迁为用户(人)为中心,这一变化必然将增加过去所有经典模型的复杂性,并对从业者提出了更高的要求。
欢迎大家提出自己的见解,或者提出自己认为重要的模型。
星哥 白皮书太酷了!